При работе с подсистемами ЕГИСЗ для получения нормативно-справочной информации необходимо взаимодействовать с ФРНСИ (федеральный реестр нормативно-справочной информации в сфере здравоохранения) - https://nsi.rosminzdrav.ru/.
Для взаимодействия с внешними системами ФРНСИ предоставляет интеграционный веб-сервис, работающий с архитектурой REST или по протоколу SOAP.
Обучающие материалы, документации и инструкции по работе с ФРНСИ можно скачать в разделе https://nsi.rosminzdrav.ru/#!/help.
Задача:
Получить данные справочника МКБ-10 по REST-сервису ФРНСИ.
Актуальная версия справочника на 2023-01-22T21:00:00Z - https://nsi.rosminzdrav.ru/#!/refbook/1.2.643.5.1.13.13.11.1005/version/2.22.
Алгоритм решения:
- Проанализируем методы REST-сервиса ФРНСИ.
Для получения данных справочника будем использовать метод/data. Обязательными входными параметрами метода являются толькоuserKeyиidentifier, но метод может возвращать максимум 500 записей, а справочник МКБ-10 содержит более 15 тыс. записей, поэтому будем дополнительно указыватьpageиsize, таким образом получим данные справочника постранично.
В запросе будем отправлять следующие параметры:
-
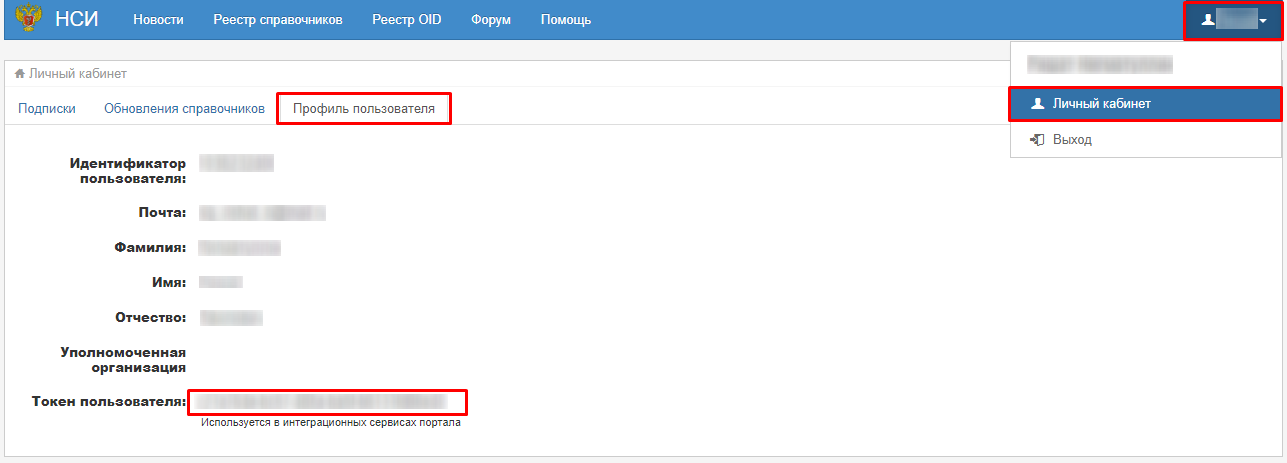
userKey- токен пользователя из личного кабинета
-
identifier- идентификатор справочника (для МКБ-10 - 1.2.643.5.1.13.13.11.1005) -
page- номер страницы -
size- количество записей на странице (500 записей)
-
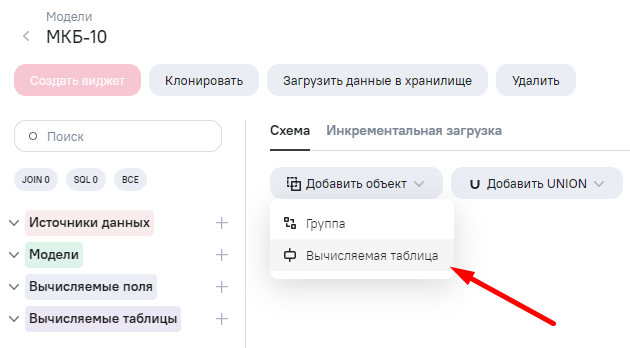
В AW создаем модель данных, а в ней вычисляемую таблицу.
-
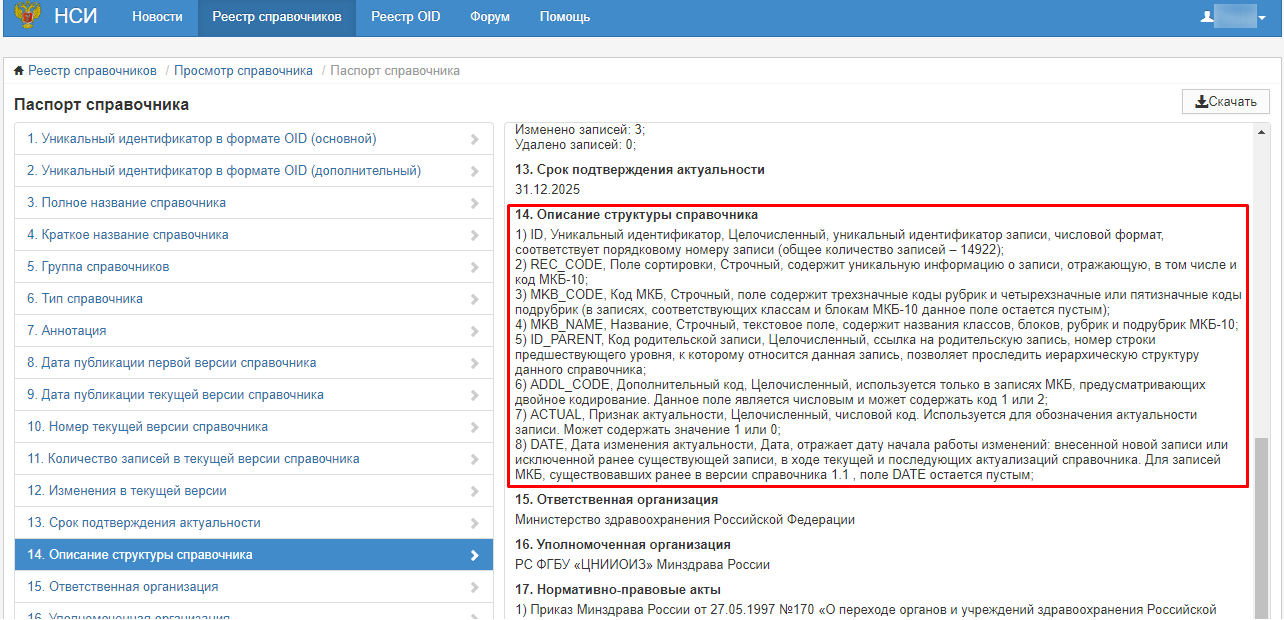
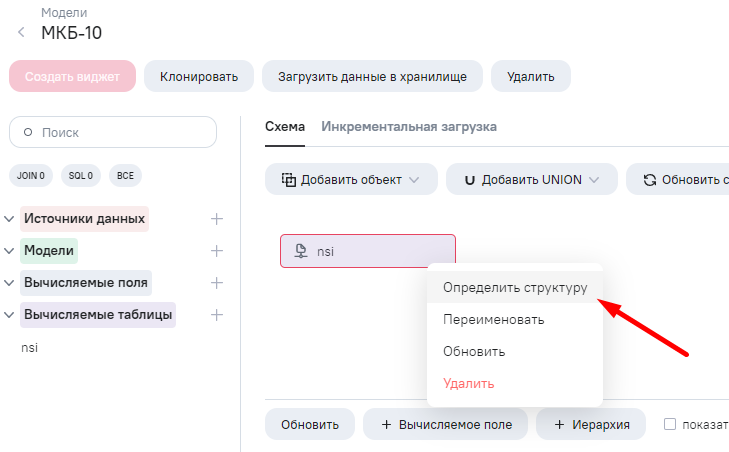
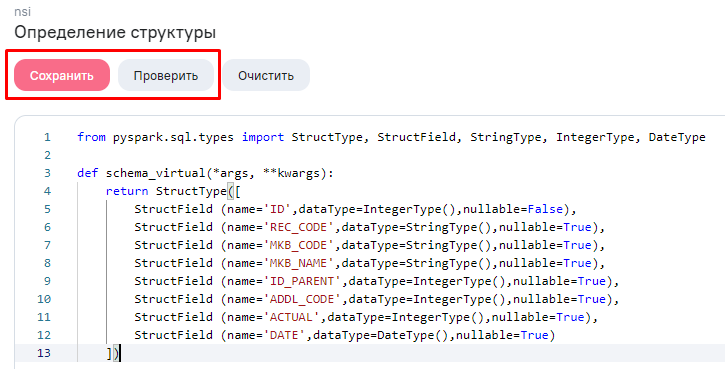
Описываем структуру данных вычисляемой таблицы в соответствии со структурой справочника МКБ-10.
Задаем поля, прописывая значение для:
-
name- код поля -
dataType- тип поля -
nullable- поле может принимать значение null
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DateType
def schema_virtual(*args, **kwargs):
return StructType([
StructField (name='ID',dataType=IntegerType(),nullable=False),
StructField (name='REC_CODE',dataType=StringType(),nullable=True),
StructField (name='MKB_CODE',dataType=StringType(),nullable=True),
StructField (name='MKB_NAME',dataType=StringType(),nullable=True),
StructField (name='ID_PARENT',dataType=IntegerType(),nullable=True),
StructField (name='ADDL_CODE',dataType=IntegerType(),nullable=True),
StructField (name='ACTUAL',dataType=IntegerType(),nullable=True),
StructField (name='DATE',dataType=DateType(),nullable=True)
])
Проверяем и сохраняем.
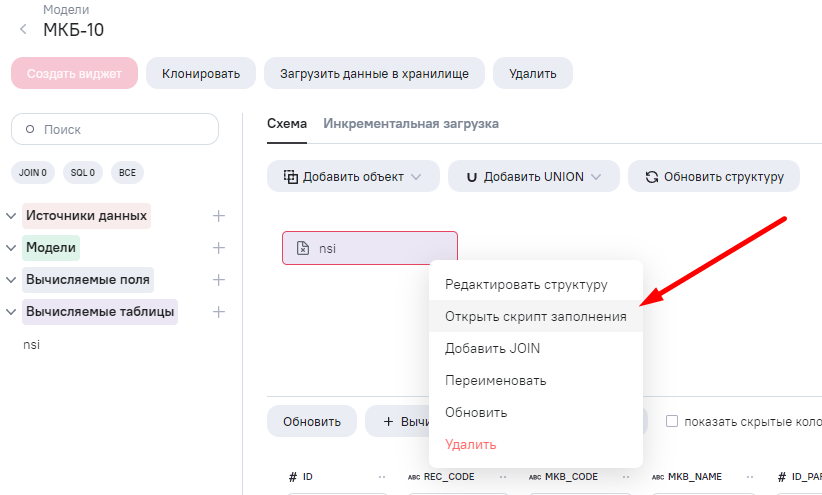
- Открываем редактор ETL, пишем код.
import requests
import json
from pyspark.sql import Row
import datetime
def after_load_virtual(df, app, spark, *args, **kwargs):
# Номер страницы
page = 1
# Количество записей справочника
total = 1
# Количество полученных записей справочника
recd = 0
rows = []
# Получение данных справочника постранично
while recd < total:
# В userKey (вместо 00000000-0000-0000-0000-000000000000) указать токен пользователя из личного кабинета
response = requests.get(url = 'https://nsi.rosminzdrav.ru:443/port/rest/data?userKey=00000000-0000-0000-0000-000000000000&identifier=1.2.643.5.1.13.13.11.1005&size=500'+'&page='+ str(page), verify=False)
if not response.ok:
raise Exception(f'Ошибка GET {response.url}. HTTP {response.status_code}: {response.text[:300]}')
response_parsed = json.loads(response.text)
if response_parsed["result"] == 'ERROR':
raise Exception(response_parsed["resultCode"] + ' — ' + response_parsed["resultText"])
total = response_parsed["total"]
line = 0
for i in response_parsed["list"]:
value = [0]*8
for j in response_parsed["list"][line]:
if j["column"] == 'ID':
value[0] = j["value"]
if j["column"] == 'REC_CODE':
value[1] = j["value"]
if j["column"] == 'MKB_CODE':
value[2] = j["value"]
if j["column"] == 'MKB_NAME':
value[3] = j["value"]
if j["column"] == 'ID_PARENT':
value[4] = j["value"]
if j["column"] == 'ADDL_CODE':
value[5] = j["value"]
if j["column"] == 'ACTUAL':
value[6] = j["value"]
if j["column"] == 'DATE':
value[7] = j["value"]
rows.append(Row(
id = int(value[0]),
rec_code = value[1],
mkb_code = value[2],
mkb_name = value[3],
id_parent = int(value[4]) if value[4] else None,
addl_code = int(value[5]) if value[5] else None,
actual = int(value[6]) if value[6] else None,
date = datetime.datetime.strptime(str(value[7]), '%d.%m.%Y') if value[7] else None
))
line += 1
recd += line
page += 1
return spark.createDataFrame(rows)
-
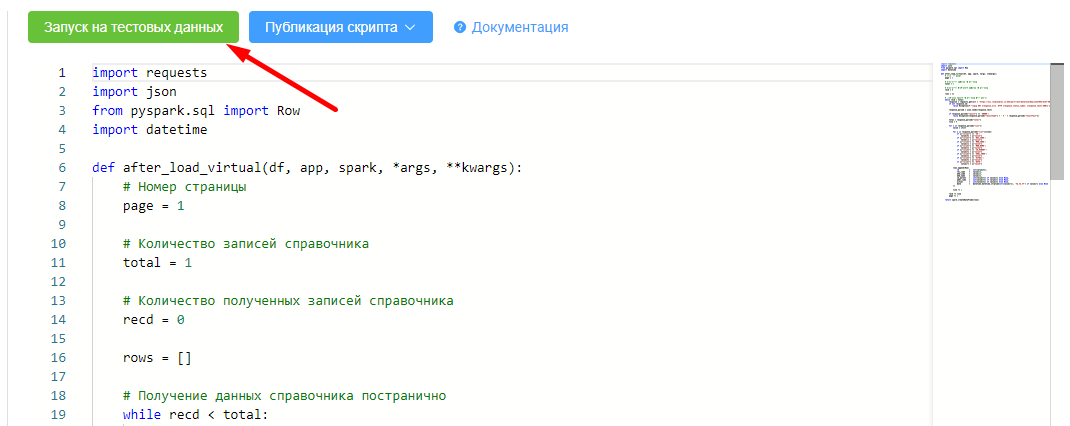
Запускаем скрипт заполнения на тестовых данных, проверяем промежуточные результаты работы.
Скрипт выполнился без ошибок, результаты нас устраивают.
-
Публикуем скрипт заполнения.
-
Переходим в модель данных, обновляем превью и видим, что данные появились.
-
Загружаем данные в хранилище.
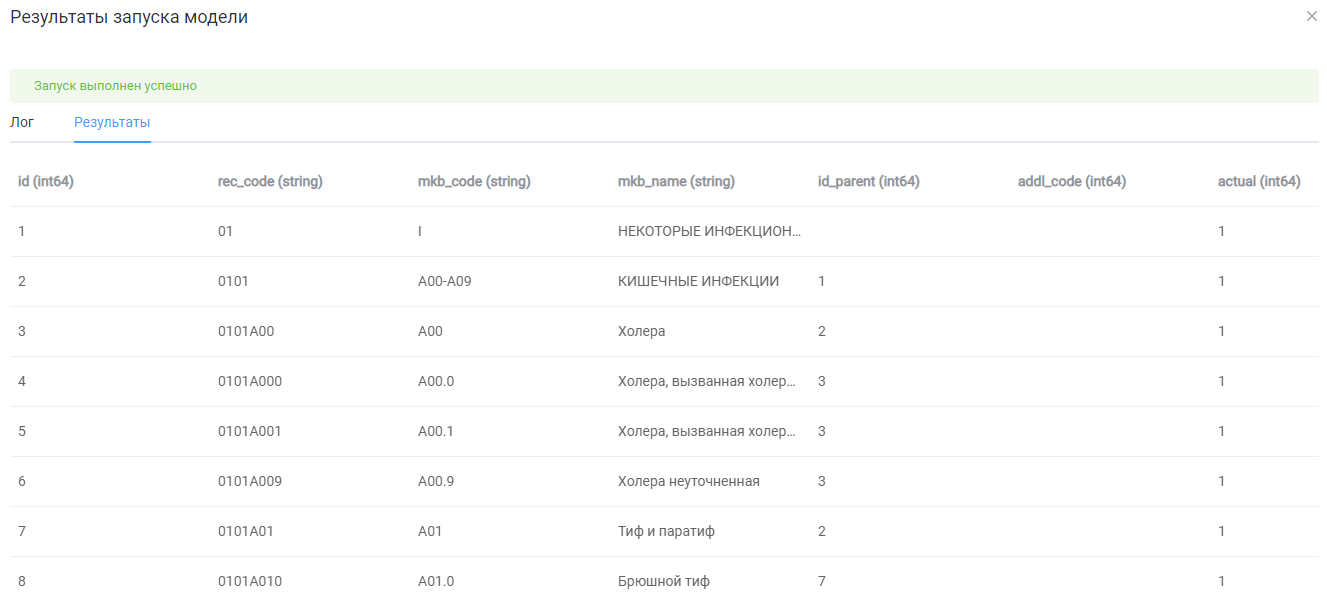
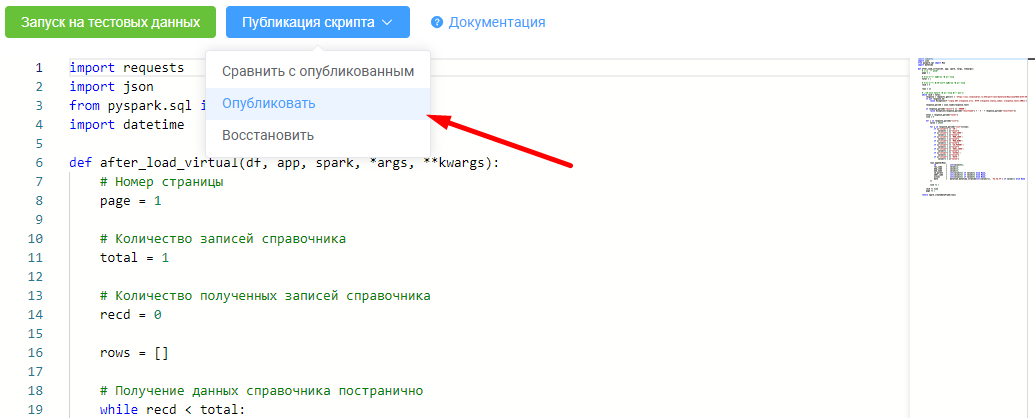
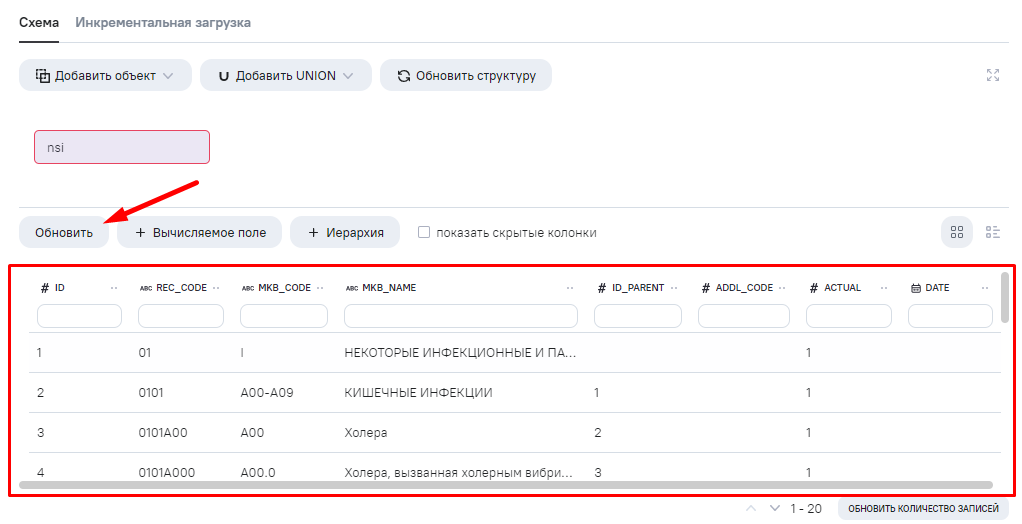
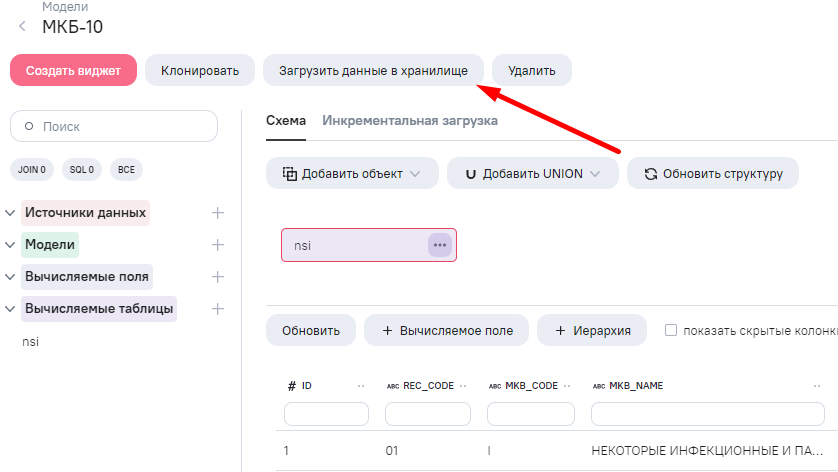
Проверяем, данные справочника МКБ-10 успешно получены из ФРНСИ.
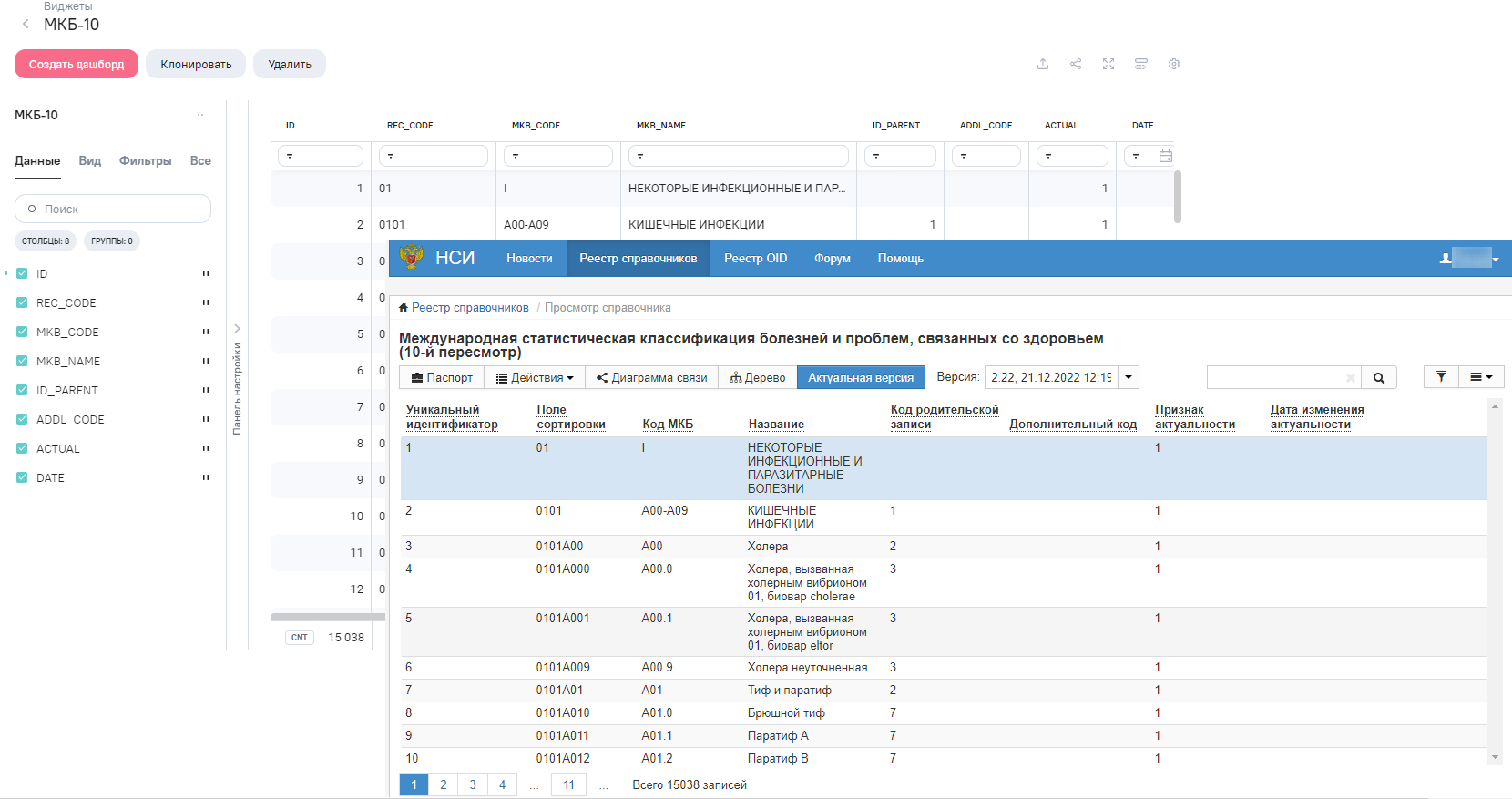
Теперь данную модель можно использовать в качестве справочника МКБ-10 при построении витрин данных.