Для выполнения заданий из этой статьи вам понадобится:
-
Доступ к Analytic Workspace (далее, AW). Для регистрации в демо-версии зайдите на сайт https://analyticworkspace.ru/ и нажмите кнопку “Получить демо-доступ”. Если у вас уже есть свой экземпляр AW, то убедитесь, что у него версия не ниже 1.25.
-
Установленный на вашем компьютере Python версии не ниже 3.10 и Jupyter. Мы предлагаем установить вам Anaconda, в составе которой есть уже все необходимые утилиты. Процедура установки и настройки Anaconda приведены в следующем разделе. Если же вы не собираетесь использовать этот пакет, то сразу переходите к разделу “Я не планирую использовать Anaconda”
Структура статьи:
- Настройка инструментов
- Задача и источники данных
- Настройка датасета для обучения
- Элементы разведочного анализа
- Обучение ML-модели
- Запуск ML-модели в AW
Настройка Anaconda и Jupyter на вашем компьютере
Для обучения модели рекомендуется использовать Jupyter Notebook. Самый простой способ установить и настроить его у себя на компьютере - это использовать Anaconda.
1. Перейдите на официальный сайт проекта https://www.anaconda.com/download. Вам сразу предложат зарегистрироваться, можно нажать “Skip registration”.
2. Выберите вашу операционную систему и скачайте установочный пакет.

Дальнейшие шаги будут приведены на примере операционной системы Windows.
3. Запустите мастер установки и проследуйте его шагам со значениями по умолчанию.
4. После окончания установки запустите Anaconda Navigator. Для Windows иконка для запуска находится в меню “Пуск”. При первом запуске навигатор может предложить вам обновиться, последуйте этой рекомендации.
5. Найдите в окне навигатора Jupyter Lab и запустите его.

6. Откройте терминал и установите необходимые для работы с Analytic Workspace библиотеки.
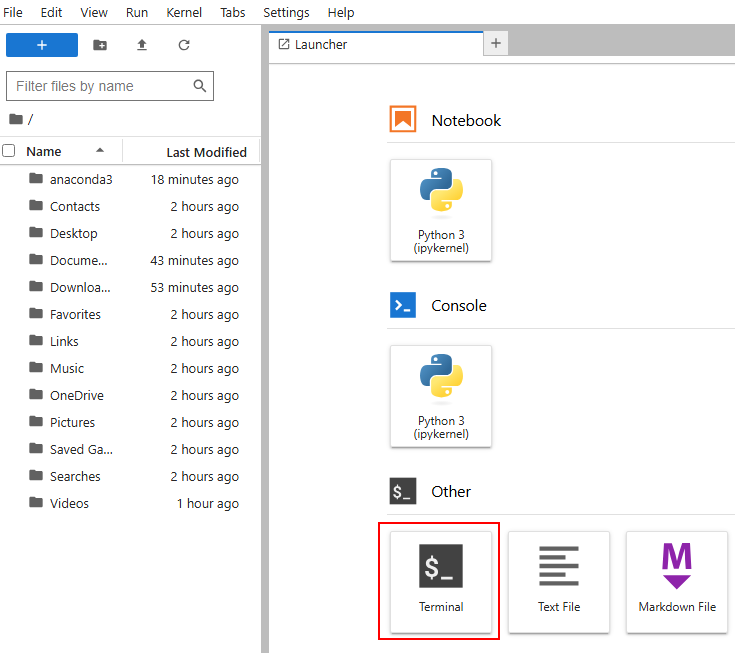
6.1. Обновите средства доставки пакетов. Для в терминале введите команду
python -m pip install --upgrade pip wheel setuptools
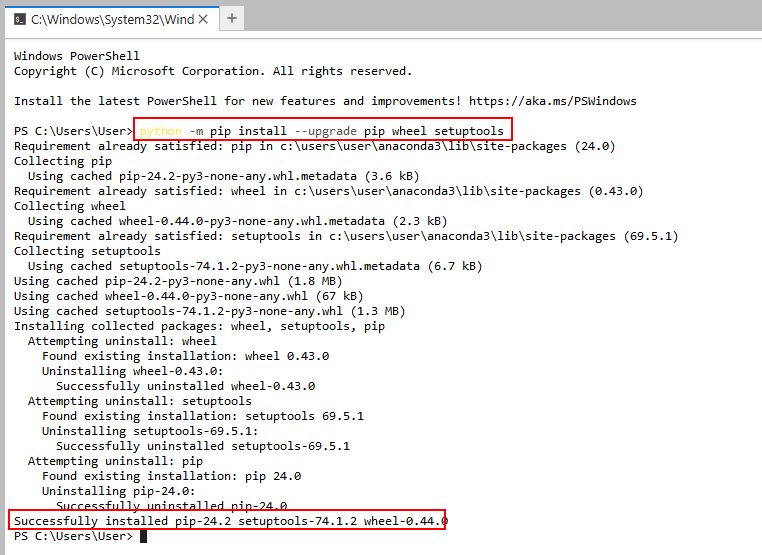
6.2. Установите библиотеку для подключения к Analytic Workspace (вместе с ML зависимостями) и средства обучения моделей catboost.
pip install analytic-workspace-client[ml] catboost
7. Проверим, что всё установилось правильно.
7.1. Создайте новый notebook.
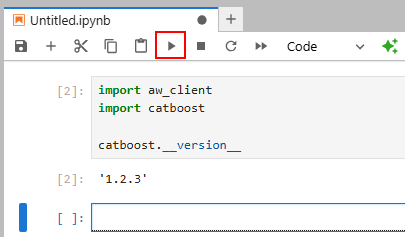
7.2. В первой ячейке наберите
import aw_client
import catboost
catboost.__version__
и запустите её.
8. Если в процессе установки у вас возникли трудности, то вы можете обратиться к официальной документации проекта https://docs.anaconda.com/anaconda/install/.
Я не планирую использовать Anaconda
Здесь информация для тех, кому установка Anaconda по каким либо причинам не подходит.
1. Если у вас уже установлен Python и Jupyter (Notebook или Lab), то для работы вам нужно будет установить в виртуальное окружение пакеты
$ pip install --upgrade pip wheel setuptools analytic-workspace-client[ml] catboost
2. Вы планируете воспользоваться облачным Jupyter (например, Google Colab). В этом случае, пакеты нужно будет установить в первой ячейке ноутбука
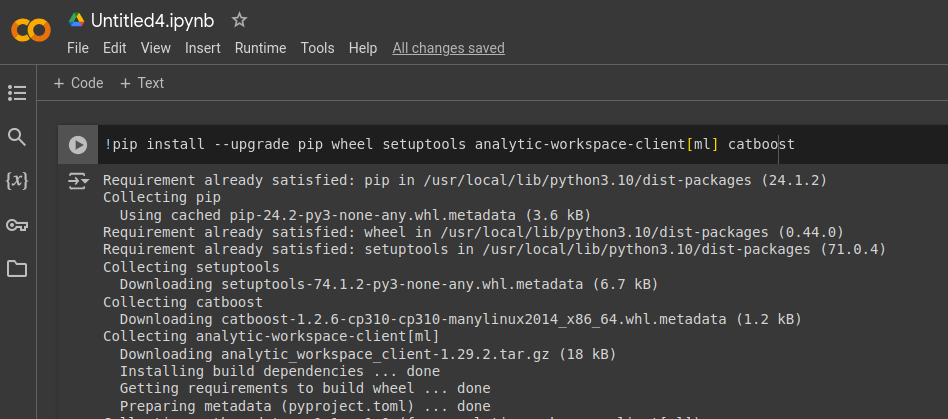
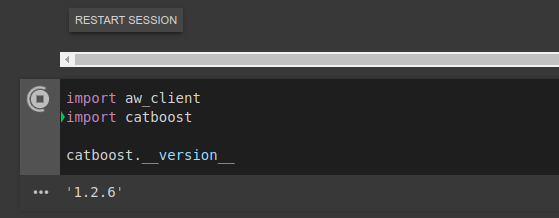
и проверить установку
3. Можно использовать для разработки ML-моделей Visual Studio Code. Вот инструкция по установке и настройке.
Задача и источник данных
Мы будем решать задачу прогнозирования для вымышленной австралийской компании KPMG, которая занимается продажами велосипедов, а также оборудования и запчастей для них.
Источник данных представлен xlsx файлом, который можно скачать по ссылке.
В файле есть 4 листа:
- Transactions - данные транзакций по продажам за 2017 год;
- CustomerDemographic - социально-демографические признаки покупателей;
- CustomerAddress - адреса покупателей;
- NewCustomerList - список новых покупателей.
Задача состоит в том, чтобы спрогнозировать продаж по списку новых покупателей в текущем году.
Для начала создадим в Analytic Workspace источник данных. Зайдите в раздел “Источники” и создайте новую запись с типом “Файл”. В поле с файлом выберите скачанный по ссылке Excel-файл.
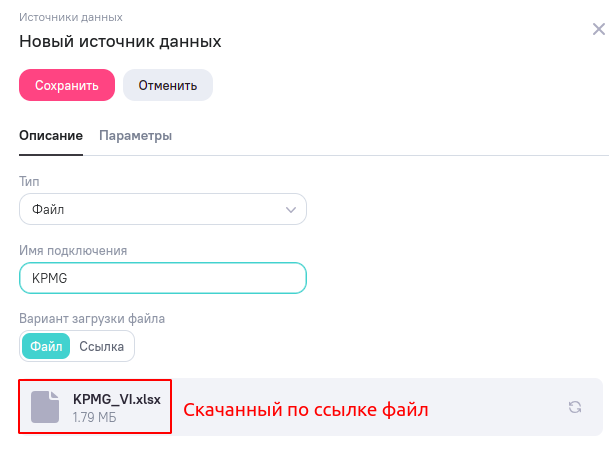
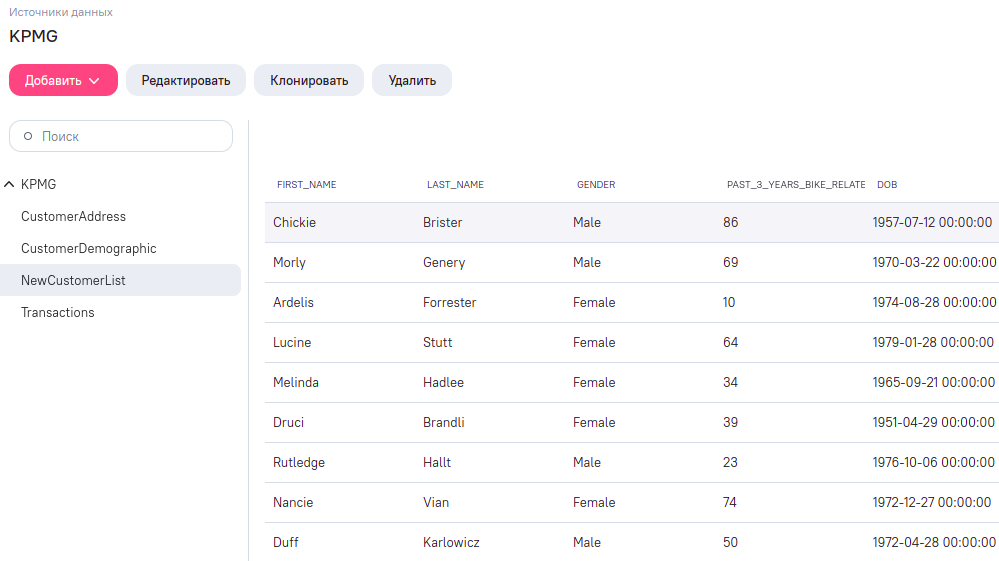
Нажмите “Сохранить”. Если всё прошло хорошо, то через некоторое время после сохранения при открытии источника вы увидите все четыре таблицы с данными (а до этого, система может сообщать, что “Обработка источника ещё не завершена”).
Настройка датасета для обучения в AW
Датасет для обучения ML-модели будет представлен логической моделью данных в Analytic Workspace. Для этого, перейдите в раздел “Модели” и добавьте новую модель.
Далее:
- Переименуйте созданную модель;
- Добавьте созданный выше источник данных;
- Вытащите на панель редактирования таблицы Transactions, CustomerDemographic и CustomerAddress;
- Над таблицей Transactions нужно выполнить группировку по полю customer_id и подсчитать сумму продаж. Для этого добавьте SQL блок: нажмите кнопку “Добавить объект”, выберите “ETL-блок” и в списке найдите “SQL-блок”. Вложите таблицу Transactions внутрь добавленного блока и укажите текст SQL-запроса
select
customer_id,
round(sum(list_price), 2) as summa
from transactions
where order_status = 'Approved'
group by customer_id
- Свяжите объекты в редакторе модели с помощью LEFT JOIN по ключу customer_id;
- Добавьте ещё один SQL-блок и поместите туда все таблицы в редакторе модели. В тексте SQL запроса этого блока укажите
select
gender,
case
when dob is null then round(mean_age, 0)
when age > 100 then age - 100
else age
end as age,
coalesce(past_3_years_bike_related_purchases, mean_past_3_years_bike_related_purchases) as past_3_years_bike_related_purchases,
job_title,
job_industry_category,
wealth_segment,
deceased_indicator,
owns_car,
coalesce(tenure, 0) as tenure,
case
when postcode is null then mode_postcode
else left(postcode, 2)
end as postcode,
state,
coalesce(property_valuation, mode_property_valuation) as property_valuation,
summa
from (
with mean_values as (
select
round(mean(age), 0) as mean_age,
round(mean(past_3_years_bike_related_purchases), 0) as mean_past_3_years_bike_related_purchases,
mode(left(postcode, 2)) as mode_postcode,
mode(property_valuation) as mode_property_valuation
from child
)
select * from child cross join mean_values
)
В результате всех действий у вас должна получиться следующая структура модели данных
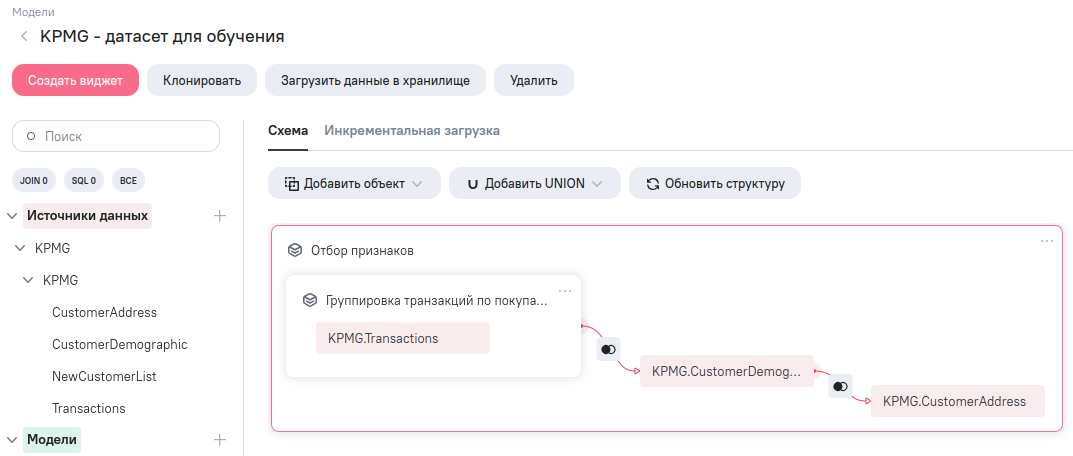
Далее, перейдите в ETL-редактор, нажав пиктограмму в правом верхнем углу редактора модели
и там добавьте ETL-скрипт:
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
def after_all(df, spark, app):
"""
Функция, которая выполнится после всех действий с датасетом
"""
norm_job_title_udf = udf(lambda jt: norm_job_title(jt), StringType())
df = df.withColumn('job_title', norm_job_title_udf(df.job_title))
return df
def norm_job_title(job_title):
"""
Возвращает нормализованное представление job_title
"""
if not job_title:
return job_title
toks = job_title.rsplit(' ', 1)
if toks[-1] in ('I', 'II', 'III', 'IV'):
return toks[0]
return ' '.join(toks)
После добавления скрипта в ETL-редактор нажмите “Публикация скрипта” → “Опубликовать”.
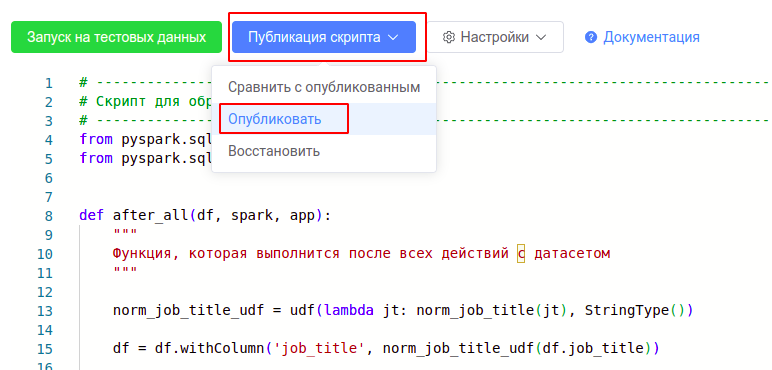
Вернитесь на вкладку с редактором модели и нажмите кнопку “Обновить” в нижней области с данными. Если всё прошло хорошо, то в этой части экрана вы увидите предпросмотр полученного датасета.
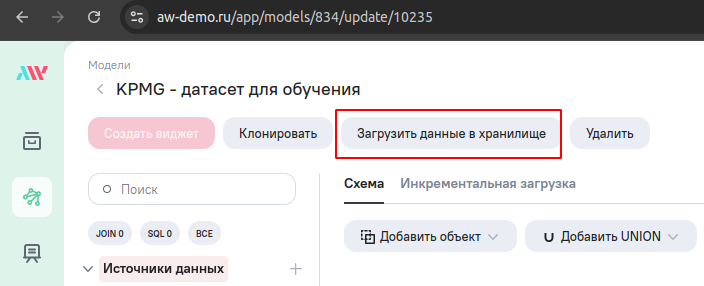
Загрузите данные в хранилище. Для этого, в редакторе модели нажмите кнопку “Загрузить данные в хранилище”.
Дождитесь окончания процесса загрузки данных. Об этом придет уведомление.
Элементы разведочного анализа
Analytic Workspace может использоваться не только для сбора обучающего датасета ML-модели, но и для проведения разведочного анализа. Для этого, создайте виджеты на подготовленной модели AW.
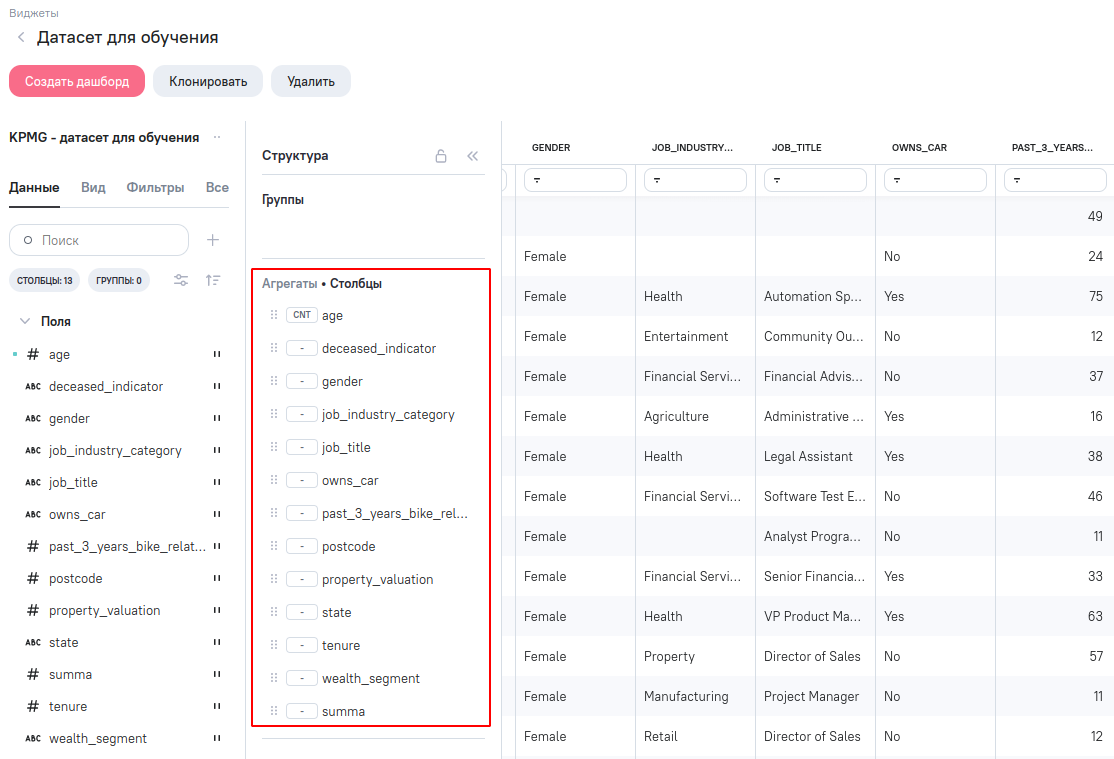
Можно посмотреть весь датасет, создав виджет “Таблица”.
Или можно проверить гипотезу о том, что владельцы автомобилей (признак owns_car) делают около-велосипедные покупки в общем и в среднем существенно на меньшую сумму.
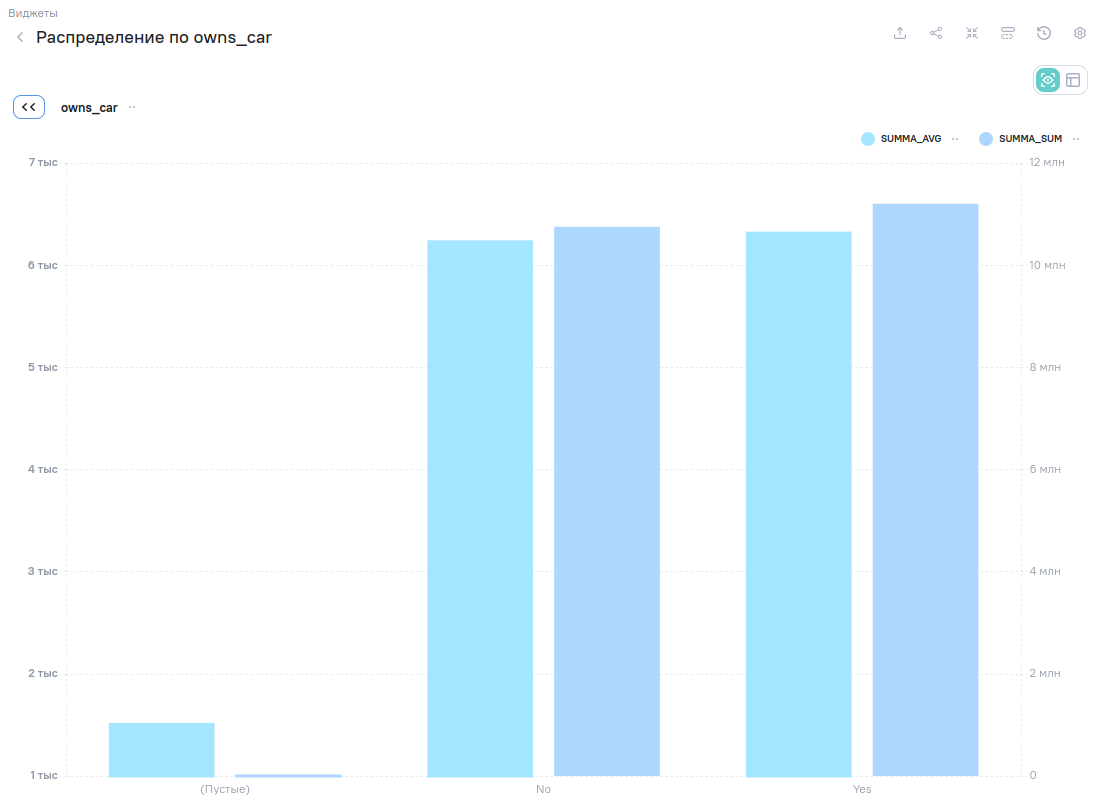
Мы видим, что данная гипотеза оказалась неверна. Владельцы автомобилей и в среднем и в общем делают покупок даже чуть больше, чем не владеющие ими.
Обучение ML-модели
Обучение модели будем производить в Jupyter Notebook. Мы его настраивали в первых разделах статьи, и вот настало его время.
Сначала настроим себе доступ из Jupyter к данным модели. Это делается при помощи специальных токенов доступа.
Для получения токена доступа перейдите по URL https://aw-demo.ru/data-master/get-token (если используете свой экземпляр AW, то замените aw-demo.ru на ваш домен).
Откроется страница управления токенами доступа к данным AW. Если на момент перехода по пути /data-master/get-token вы были не авторизованы в AW, то вас попросят вернутся в личный кабинет для входа. Войдите в систему и перейдите по URL ещё раз.
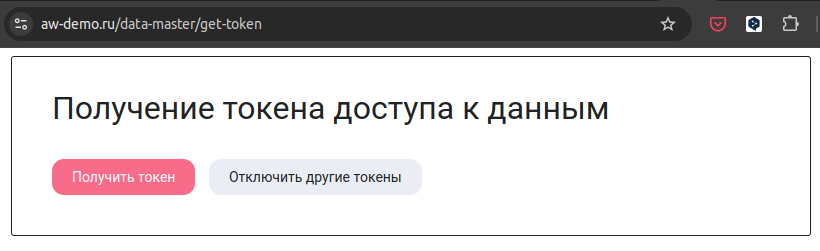
- Нажмите кнопку “Получить токен”;
- Убедитесь, что токен выдается на вашего пользователя;
- Укажите срок действия токена в днях (можно указать много: 3000, например).

После нажатия на кнопку “Получить” вы увидите значение выданного токена.
Скопируйте значение токена со страницы и держите в секрете! С его помощью можно прочитать данные всех моделей AW, к которым у вас есть доступ. Если есть подозрение, что токен был скомпрометирован, то жмите кнопку “Отключить другие токены”. Система пересоздаст внутренний ключ шифрования вашего пользователя, и все ранее выданные токены станут недействительными.
Теперь надо сохранить указанный токен в файл на вашем компьютере. Хотя, можно использовать токен напрямую в тексте вашего Jupyter-ноутбука, но мы специально не будем поощрять порочную практику (ведь, мы можете передать файл с ноутбуком кому-нибудь, и этот человек увидит значение вашего токена).
Выберите (или создайте) папку на компьютере, в которой вы будете вести работу, и создайте там файл token.txt. Внутрь файла вставьте значение токена из буфера обмена. Без переводов строк, лишних пробелов и т.п. Сохраните файл.
Далее, перейдите в Jupyter Notebook и в первой ячейке вставьте текст
# Первая ячейка
from aw_client import Session
token = open('../tokens/aw-demo-akvarats.txt').read()
session = Session(token=token, aw_url='https://aw-demo.ru')
В вашем случае, вместо ‘…/tokens/aw-demo-akvarats.txt’ указываем путь к файлу с токеном доступа. И, если вы работаете не с демо-сервером, то замените ‘https://aw-demo.ru’ на адрес вашего AW.
Во второй ячейке добавьте команду на чтение созданного в AW датасета
# Вторая ячейка
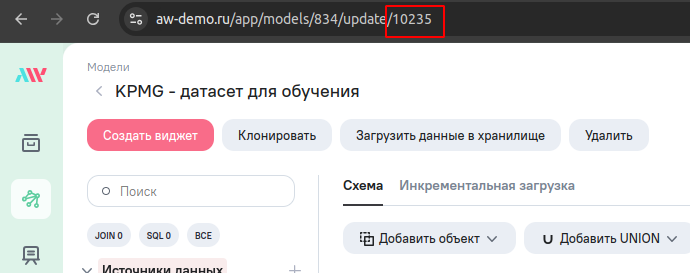
df = session.load_model(model_id=10235)
df
Вместо 10235 укажите идентификатор модели AW с вашим датасетом. Его можно узнать из адресной строки браузера. Это последние цифры в URL просмотра или редактирования модели AW.
В итоге, первые две ячейки вашего Jupyter-ноутбука должны выглядеть как-то так
Выполните последовательно обе ячейки (нажав обведенную кнопку на панели инструментов).
Ниже второй ячейки должно появиться отображение загруженного из AW датасета.
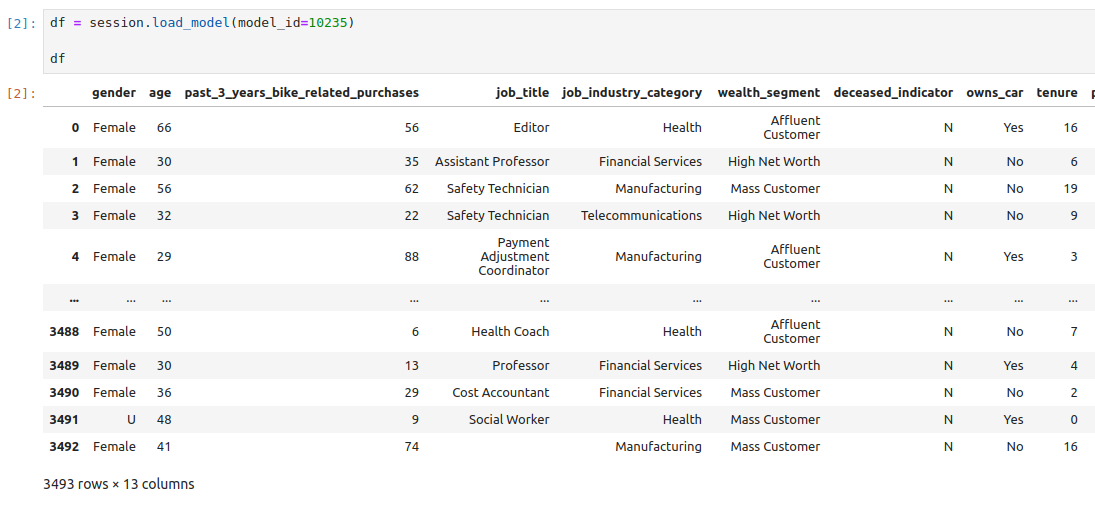
Если вместо датасета отобразилась ошибка, то там в самом конце будет указана причина. Например, если вы используете неверный токен доступа, то увидите такое сообщение
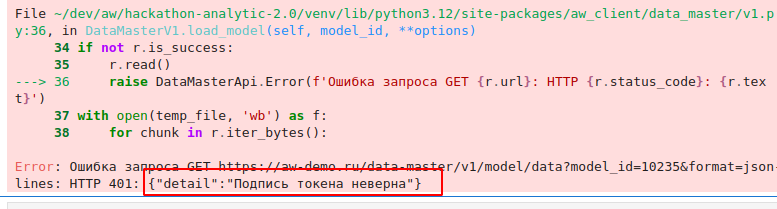
А если указали идентификатор модели, к которой у вас нет доступа, то такое сообщение
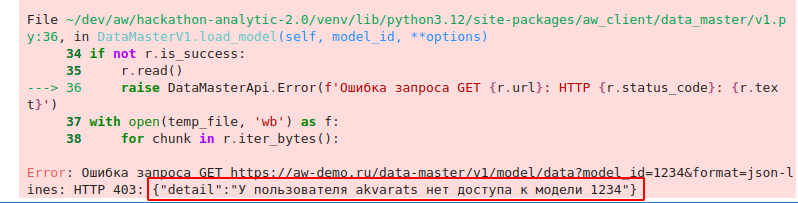
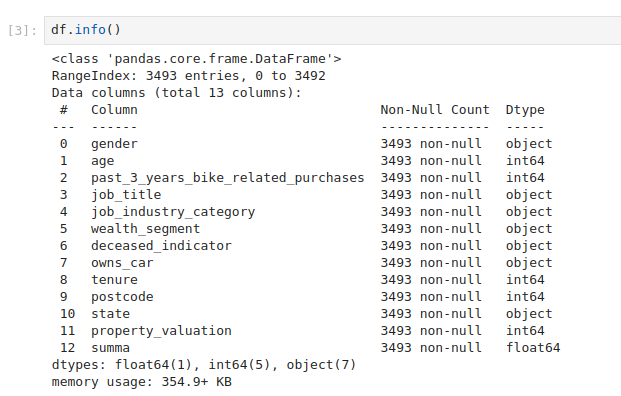
В следующей ячейке посмотрим, какие столбцы есть в датасете, и сколько значений в каждом столбцы принимает null-значения.
# Третья ячейка
df.info()
В следующей ячейке напишем функцию для обучения ML-модели
# Четвертая ячейка
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor, Pool
CAT_FEATURES = [
'gender',
'job_title',
'job_industry_category',
'wealth_segment',
'deceased_indicator',
'owns_car',
'postcode',
'state',
]
FEATURES = [
'age',
'past_3_years_bike_related_purchases',
'tenure',
'property_valuation',
] + CAT_FEATURES
TARGET = 'summa'
def fit_model(df, random_state=1):
"""
Процедура обучения ML-модели
"""
X_train, X_val, y_train, y_val = train_test_split(df[FEATURES], df[TARGET], test_size=0.1, random_state=random_state)
train_pool = Pool(X_train, y_train, cat_features=CAT_FEATURES)
eval_pool = Pool(X_val, y_val, cat_features=CAT_FEATURES)
model = CatBoostRegressor(random_seed=random_state, learning_rate=0.005)
model.fit(train_pool, eval_set=eval_pool, plot=False, verbose=False, use_best_model=True)
return model
И в последней ячейке запустим обучение ML-модели и регистрации её в реестре AW. Назовем модель MyFirstModel_akvarats_demo.
Названия ML-моделей являются уникальными среди всех пользователей AW. Если вы работаете на демо-сервере и решили выбрать какое-то слишком общее имя для модели (например MyFirstModel), то рекомендуется добавить после имени ещё какую-то уникальную последовательность символов (например, имя вашего пользователя, как и приведено в тексте ячейки). Иначе, если модель с таким именем уже была зарегистрирована, то вы увидите ошибку MlflowException: API request to endpoint /api/2.0/mlflow/experiments/get-by-name failed with error code 403 != 200. Response body: 'Permission denied'. Значит, пришло время выбрать другое имя для модели.
# Последняя ячейка
experiment_id = session.mlflow.setup_experiment('MyFirstModel__akvarats_demo')
with session.mlflow.start_run(experiment_id=experiment_id):
model = fit_model(df)
session.mlflow.log_metrics(model.get_best_score()['validation'])
session.mlflow.catboost.log_model(model, 'model', registered_model_name='MyFirstModel__akvarats_demo')
После успешного выполнения ячейки вы увидите сообщение, что модель успешно создана и первая версия модели успешно зарегистрирована.
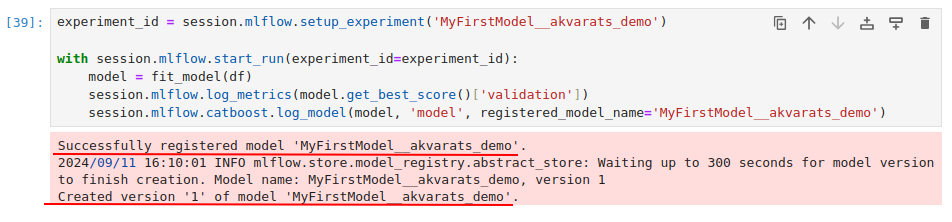
Теперь посмотрим на реестр ML-моделей в Analytic Workspace. Для этого, перейдите по адресу https://aw-demo.ru/mlflow (подставьте ваш домен, если вы работаете не на демо-сервере).
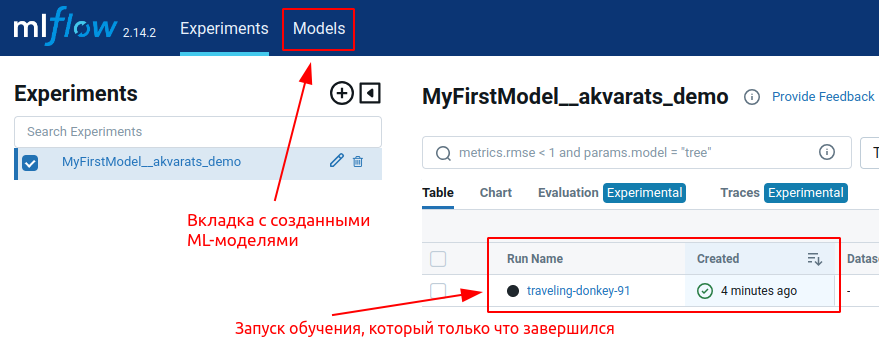
Здесь вы увидите запуск эксперимента с обучением ML-модели, который только что завершился. Нажмите кнопку “Models” в верхней панели, чтобы увидеть только что обученную ML-модель.
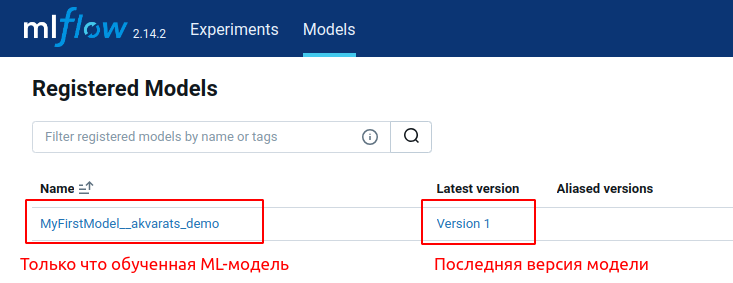
При повторном обучении ML-модели с этим же именем в реестре будут регистрироваться новые версии с последовательными номерами. Какие-то версии будут удачными, какие-то не очень. Чтобы только указать AW, какая версия модели является используемой при выполнении прогнозирования, давайте нужной версии назначим так называемый алиас alias).
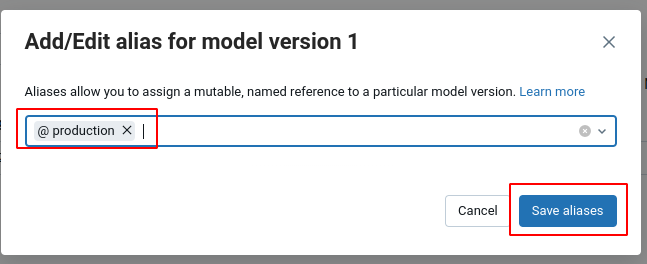
Для этого, провалитесь внутрь модели и в списке версий для нужной записи в столбце Aliases нажмите Add
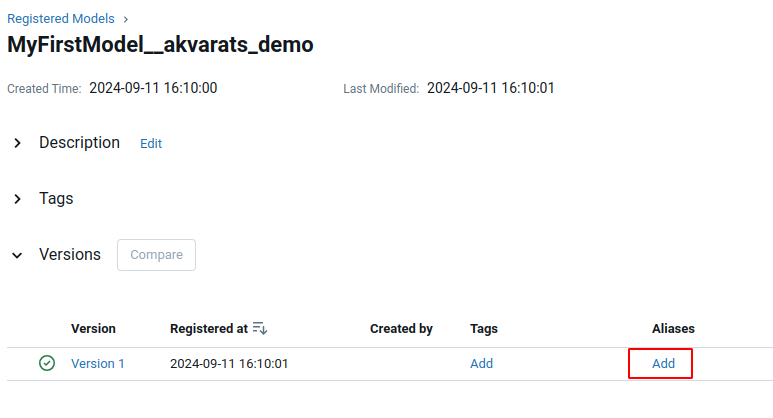
Укажите алиас production.
Запуск ML-модели в AW
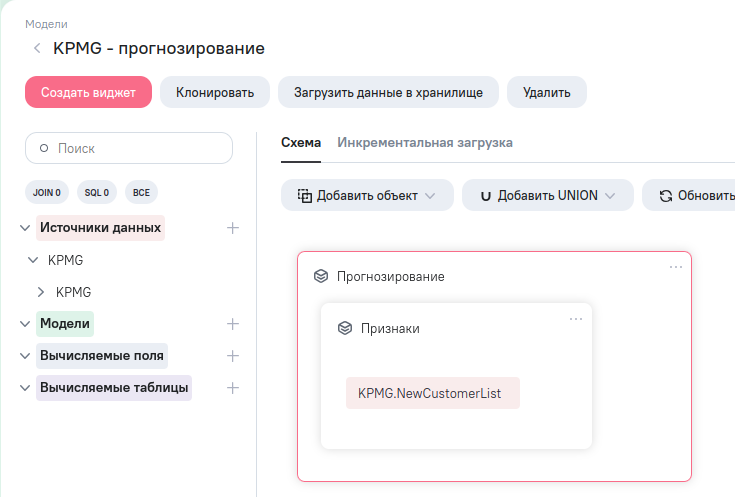
Теперь настроим прогнозирование для таблицы NewCustomerList. Для этого, в AW надо будет создать ещё одну модель, которая будет основана на этой таблице источника.
В таблице NewCustomerList присутствуют все столбцы, использовавшиеся при обучении, кроме age. Вычислим это поле на основе даты рождения нового покупателя (столбец DOB). Плюс, с помощью SQL блока перечислим признаки в том же порядке, в котором они поступали на обучение модели (см. четвертая ячейка ноутбука)
select
floor(months_between(current_date(), dob) / 12) as age,
past_3_years_bike_related_purchases,
tenure,
property_valuation,
gender,
job_title,
job_industry_category,
wealth_segment,
deceased_indicator,
owns_car,
left(postcode, 2) as postcode,
state
from child
И результаты работы SQL-блока поместим внутрь ETL-блока “Классификация/регрессия с ML- моделью”.
Получаем структуру модели данных
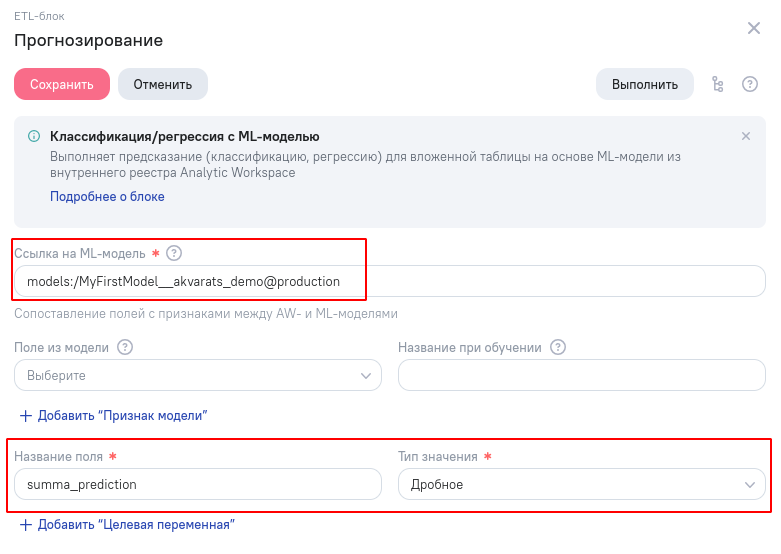
В параметрах блока ML-прогнозирования указываем:
- Путь к используемой ML-модели, включая привязку к алиасу. Текст models:/ перед названием ML-модели обязателен. Алиас production указывается после названия модели через символ @;
- Как будет называться и какого типа будет столбец с результатами прогнозирования.
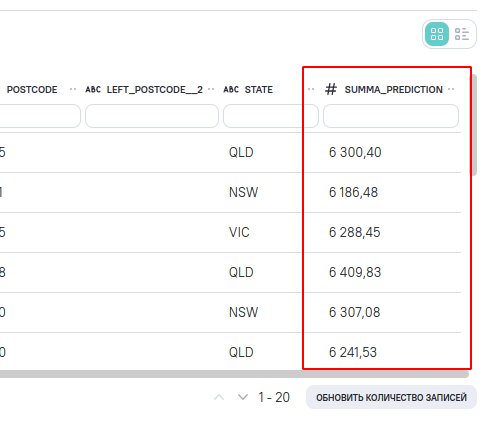
После сохранения параметров блока прогнозирования и обновления данных предпросмотра можно увидеть спрогнозированные значения в столбце summa_prediction.
После загрузки данных в хранилище спрогнозированные значения можно будет использовать в виджетах и информационных панелях.
Поздравляем, вы прошли начальное обучение по применению ML-прогнозирования в Analytic Workspace.
Примечания
Машинное обучение доступно в Analytic Workspace, начиная с версии 1.25.
Доступные библиотеки машинного обучения:
| Название | Для чего |
|---|---|
| scikit-learn | Классическое машинное обучение, простые модели |
| pytorch | Глубокое обучение, нейронные сети |
| catboost | Градиентный бустинг на деревьях решений |
| statsmodels | Статистические модели, прогнозирование временных рядов |
| prophet | Прогнозирование временных рядов |