Модель данных в AW BI - это основа для ваших аналитических отчетов и дашбордов. Чтобы ваша аналитика была актуальной, данные модели необходимо загрузить в хранилище системы.
Процесс загрузки (синхронизации) - это важный этап, который включает в себя сбор данных из различных источников, их преобразование согласно вашей бизнес-логике и загрузку в целевое хранилище ClickHouse.
План статьи:
-
Методы запуска загрузки данных
- ручная загрузка
- автоматическое обновление
- по времени(неделя/cron-строка)
- по задаче
-
Airflow: Принцип работы и роль в AW BI
- Как Airflow управляет процессом.
- Архитектура Airflow
- Нюансы времени и расписаний
- Мониторинг и отладка в Airflow
Методы запуска загрузки данных
AW BI предлагает два основных подхода к синхронизации: ручной запуск и автоматическое обновление.
1. Ручная загрузка данных (по требованию)
Вы можете запустить обновление модели в любой момент времени, нажав кнопку “Загрузить данные в хранилище”.
- Версионирование: Каждый новый успешный ручной запуск создает новую таблицу в хранилище и удаляет самую старую версию, согласно параметру MODEL_SYNC_COUNT (количество хранимых версий). За счет версионирования происходит присвоение уникальных имен каждой версии модели.
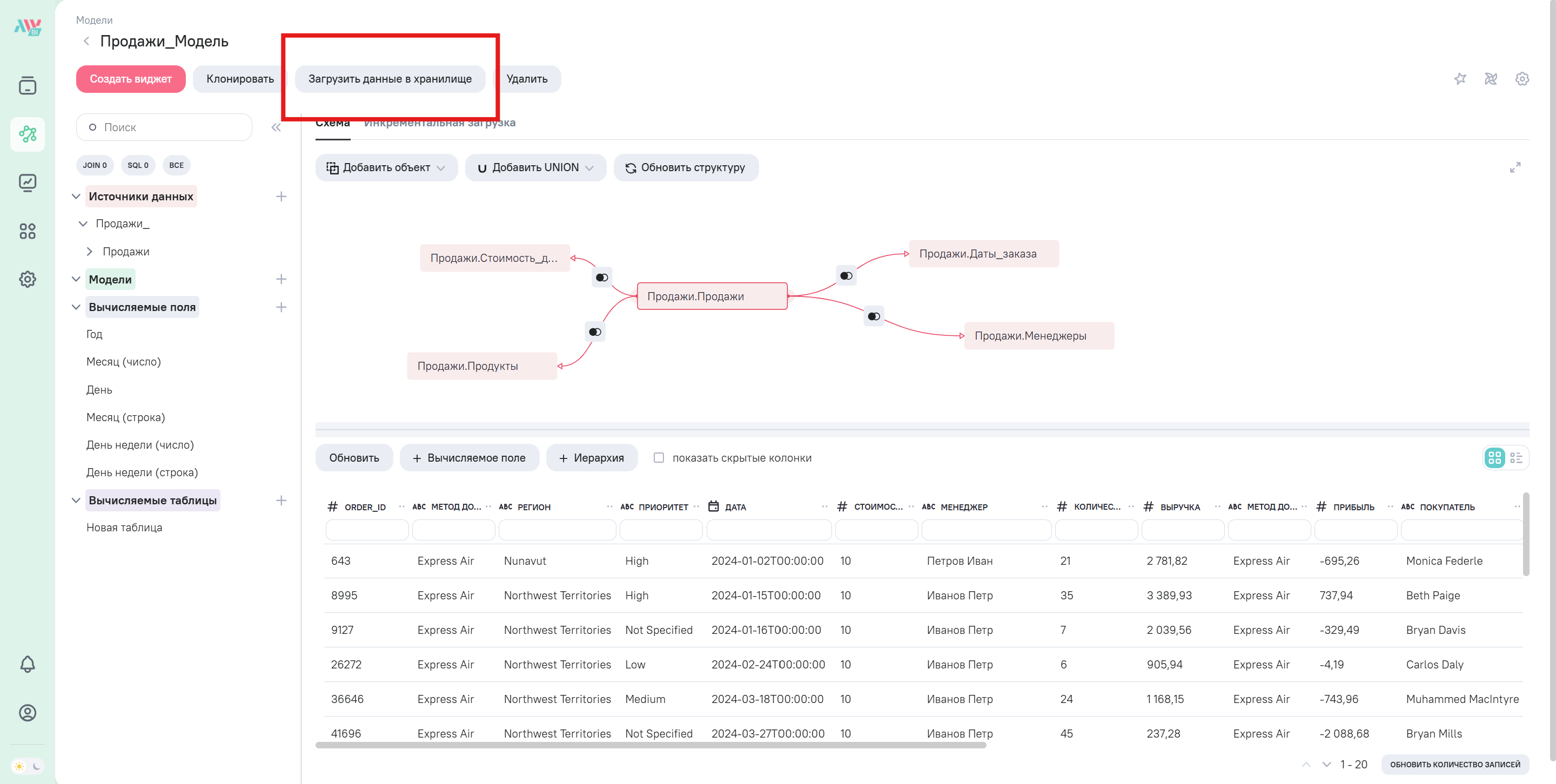
2. Автоматическое обновление данных (по планировщику)
Настройки регулярного обновления доступны в разделе “Планировщик” в настройках модели. Для этого необходимо открыть панель “Настройки” в модели и перейти далее во вкладку “Планировщик”.
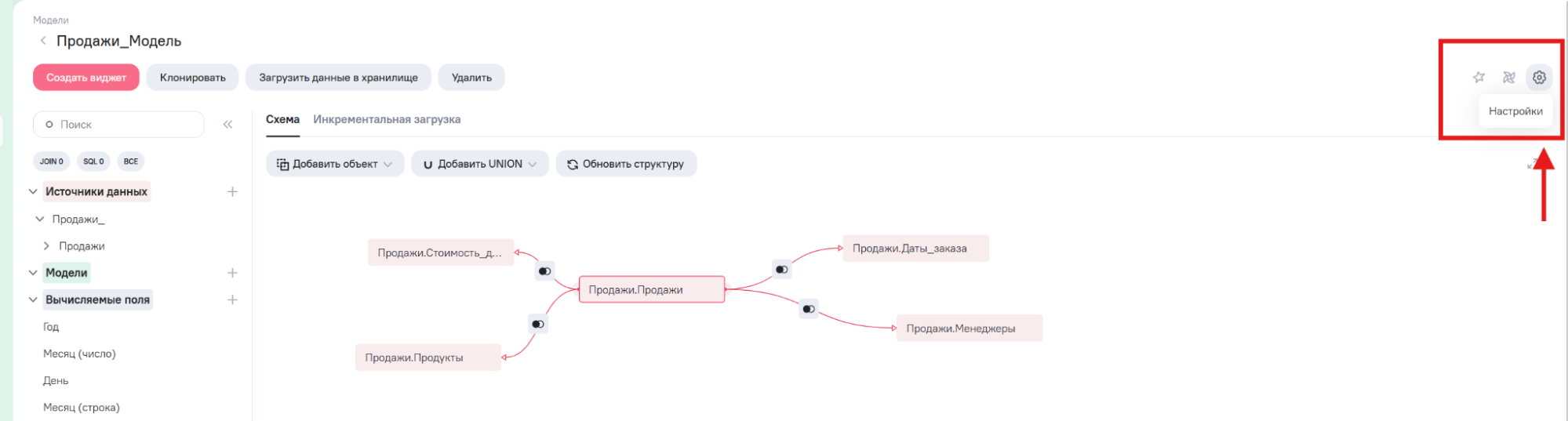
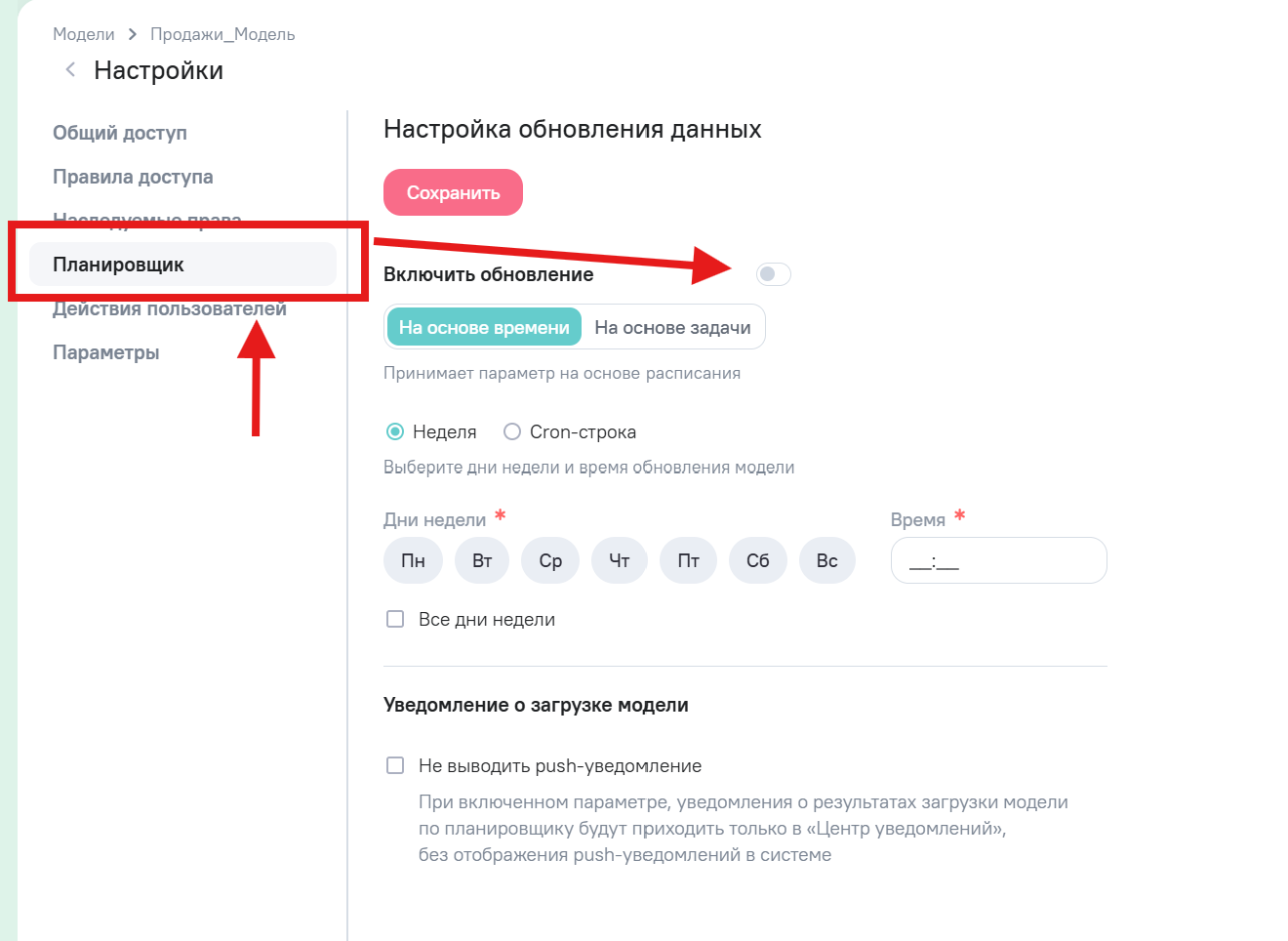
| Вариант планирования | Описание |
|---|---|
| На основе времени (Режим “Неделя”) | Обновление по фиксированному расписанию (выбранные дни недели и время). |
| На основе времени (Режим “Cron-строка”) | Для сложных и гибких расписаний. Используется Cron-выражение (например, */5 * * * * для запуска каждые 5 минут). |
| На основе задачи (По событию) | Запуск модели происходит только после успешного завершения синхронизации всех выбранных вами зависимых моделей. |
 Airflow: сердце оркестрации и ключевые нюансы
Airflow: сердце оркестрации и ключевые нюансы
За всеми процессами загрузки и обновления данных в AW обязательно стоит Apache Airflow - инструмент, являющийся золотым стандартом для оркестрации сложных рабочих процессов в дата-инжиниринге.
Для чего нужен Airflow в AW BI? 
Airflow — это мощный инструмент, который делает интеграцию ETL-процессов в AW BI бесшовной и эффективной:
- Управление порядком: Обеспечивает выполнение шагов в строго правильной последовательности.
- Параллельность: Запускает независимые шаги одновременно.
- Обработка ошибок: Контролирует статусы задач и обеспечивает логику повторов.
- Автоматическая генерация кода: AW BI автоматически генерирует описание рабочего процесса (DAG) в коде Airflow при любом изменении модели (добавлении таблиц, логики) и записывает его. Это избавляет пользователя от необходимости писать код для оркестрации.
- Синхронность: Airflow работает асинхронно (на основе событий), что позволяет системе AW BI оставаться стабильной и не блокировать пользователя, пока происходят сложные фоновые процессы.
Как Airflow управляет процессом
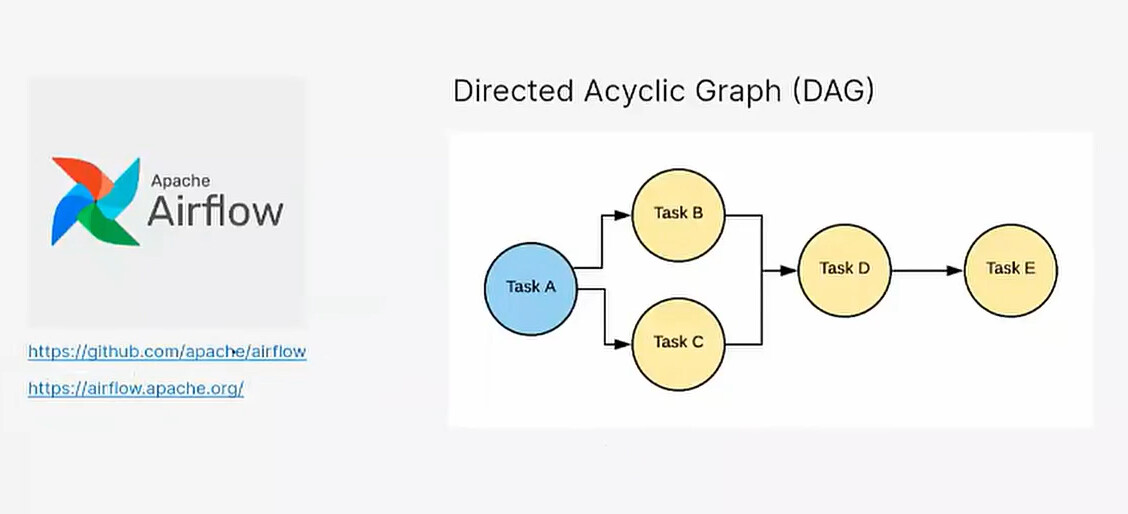
Каждый процесс загрузки данных модели в AW BI является рабочим процессом Airflow, который называется DAG (Directed Acyclic Graph) — Ориентированный Ациклический Граф.
-
DAG — это ваша модель, представленная в виде схемы, где каждый узел (шаг) называется задачей (Task).
-
Задачи — это оболочки над Операторами, которые выполняют конкретные действия (например, Transform_Spark_SQL для трансформации, Push_to_clickhouse для записи в ClickHouse).
-
Python как «Клей»: Airflow написан на Python и использует его, чтобы связать все разнородные технологии, участвующие в процессе (базы данных, Spark, ML-модели).
-
Airflow использует концепцию слотов и ограничения на параллельность, чтобы «размазывать» нагрузку по времени. Это необходимо, чтобы избежать переполнения ресурсов (Out of Memory) при одновременном запуске множества сложных задач (например, 100 задач ночью). AW BI в целом использует Airflow не только для основной синхронизации данных, но и для вспомогательных операций.
 Архитектура Airflow: кто чем управляет
Архитектура Airflow: кто чем управляет
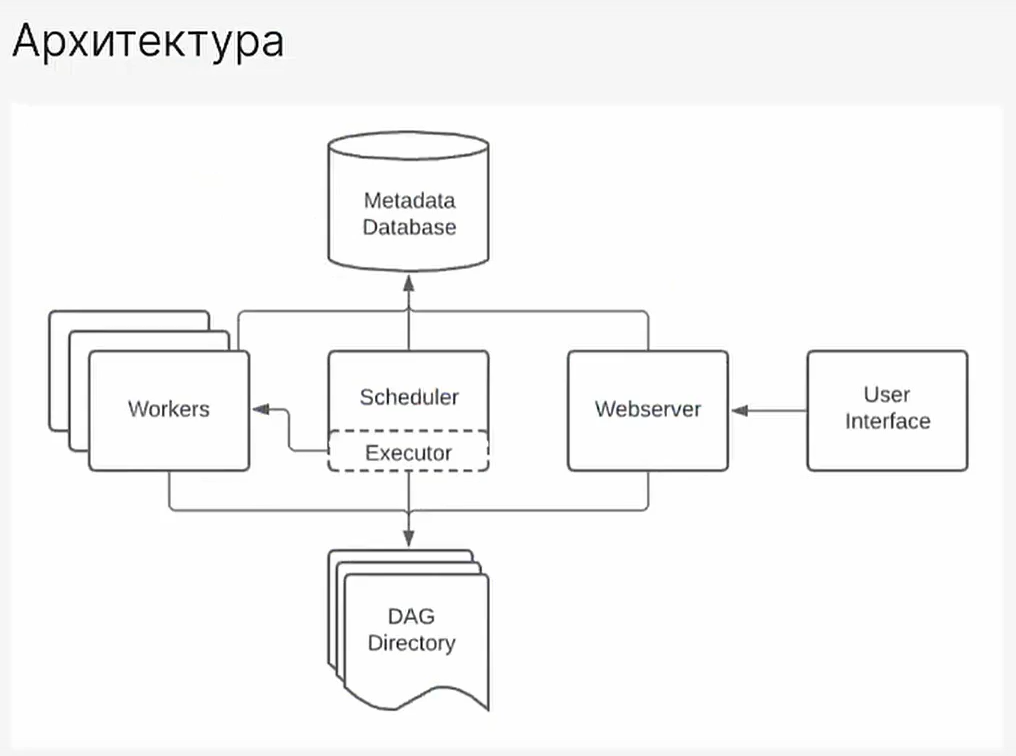
Airflow — это не единый механизм, а система, состоящая из нескольких ключевых компонентов, работающих вместе. Чтобы понять их роли, представьте систему Airflow как отдел логистики на большом складе:
| Компонент Airflow | Аналогия (Отдел Логистики) | Роль в системе |
|---|---|---|
| Шедулер (Scheduler) | Начальник отдела и Планировщик | Сердце Airflow. Он постоянно сканирует все DAG’и, определяет, когда нужно запускать задачи (по расписанию или событию) и отслеживает их статус. |
| Веб-сервер (Webserver) | Монитор руководителя | Предоставляет пользовательский интерфейс (UI), где вы видите граф процессов, логи и статусы задач. Это «приборная панель» всей системы. |
| Исполнитель (Executor) | Диспетчер задач | Определяет, где и как будут выполняться задачи. Он берет задачу у Шедулера и помещает ее в очередь для Воркеров, контролируя доступные ресурсы (слоты). |
| Воркер (Worker) | Рабочий персонал/Грузчики | Фактически выполняет код. Воркер получает задачу от Диспетчера и запускает оператор (например, выполняет Python-скрипт или Spark-запрос). |
| База Метаданных (Metadata DB) | Журнал учета и архив | Хранит всю информацию о системе: историю запусков, статусы задач, расписания, настройки и переменные. Все компоненты обращаются к ней. |
 Особенности отображения времени и расписаний
Особенности отображения времени и расписаний
Airflow имеет специфическую логику работы с расписаниями, которую важно понимать:
1. Правило первого запуска
Первый запуск по расписанию всегда начинается раньше назначенного времени. Дело в том, что Airflow разбивает всю временную ось на интервалы согласно расписанию. После создания расписания система проверяет, когда был последний запуск, и если видит, что его не было, то сразу же выполняет его в конце первого же пропущенного интервала.
2. Время в карточке запуска
Когда у модели настроен планировщик, Airflow оперирует интервалами данных, а не фактическим временем запуска, поэтому важно различать несколько характеристик, которые можно встретить в интерфейсе Airflow
| Время в Airflow UI | Что означает | Когда используется |
|---|---|---|
| Data Interval End | Конец текущего интервала согласно установленному расписанию. | Отображается как время запуска в Airflow, если у модели есть расписание (в том числе при ручном запуске). |
| Execution Date | Фактическая дата ручного запуска. | Используется в карточке, если у модели нет настроенного расписания. |
| Started и Ended | Точное время начала и окончания выполнения процесса. | Доступно в параметрах в карточке запуска. Это единственный способ увидеть действительное время работы. |
![]() Поэтому вполне логична такая ситуация, когда вы сделаете несколько ручных запусков, все они могут показать одинаковое время в поле “Data Interval End” - это будет время следующего планового интервала, а не фактическое время нажатия кнопки. Для точного отслеживания используйте параметры “Started” и “Ended”.
Поэтому вполне логична такая ситуация, когда вы сделаете несколько ручных запусков, все они могут показать одинаковое время в поле “Data Interval End” - это будет время следующего планового интервала, а не фактическое время нажатия кнопки. Для точного отслеживания используйте параметры “Started” и “Ended”.
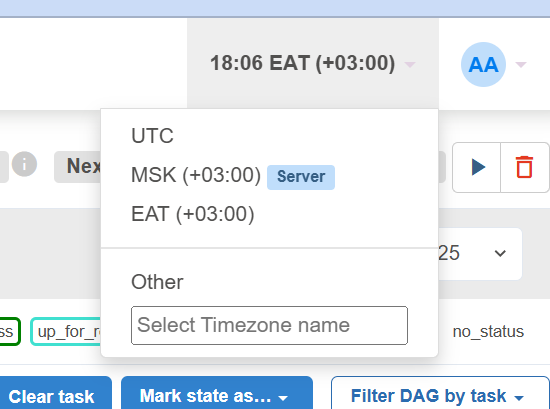
Настройка часового пояса
По умолчанию время в Airflow может быть установлено в UTC 0. Это может быть неудобно для мониторинга.
- Настройка: Для того чтобы изменить часовой пояс на нужный (например, UTC +3), необходимо в конфигурационном файле AW BI (.env) изменить параметр SERVER_TIMEZONE.
- Применение: После изменения параметра нужно перезапустить AW BI (docker compose up -d --force-recreate).
3. Мониторинг и анализ процесса
AW BI позволяет детально отслеживать процесс загрузки через интерфейс Airflow и, говоря даже о визуальном представлении процесса, это можно сделать несколькими способами.
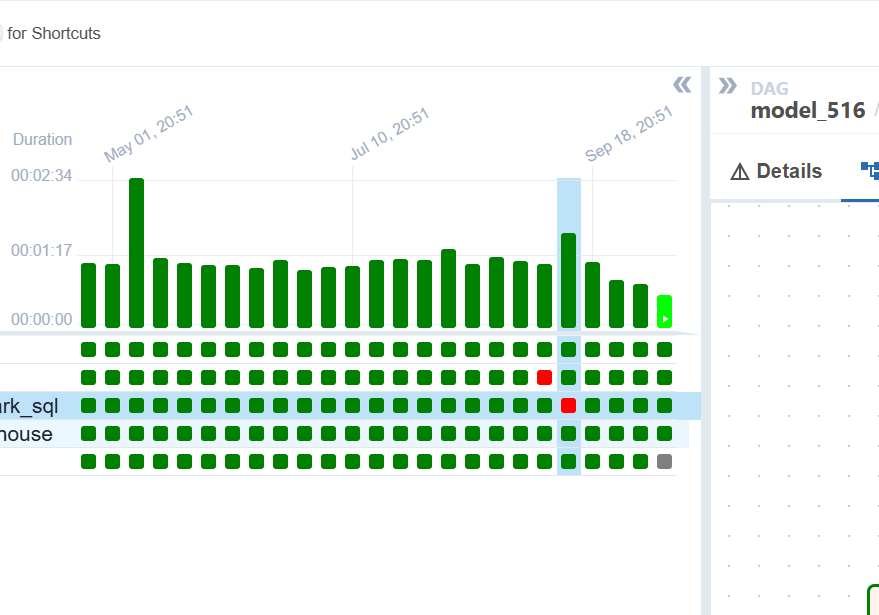

| Отображение | Для чего нужно |
|---|---|
| Виды состояний для таски | Нужны для наглядного отображения статуса выполняемой таски в момент выполнения и различаются по статусу и цвету. Каждый столбец в левой части интерфейса представляет собой отдельный запуск модели (RunID). Мигающие/горящие квадратики на графе показывают текущее состояние задач: |
| none - пока отдыхает | |
| scheduled - должна быть запущена, все зависимости выполнены | |
| queued - ждет свободный воркер | |
| running - работает | |
| success - успешно завершилась | |
| restarting - перезапустили | |
| failed - упала | |
| skipped - пропущена | |
| upstream_failed - упала предыдущая таска, которая нам нужна | |
| up_for_retry - упала, но будет перезапущена | |
| up_for_reschedule - сенсор будет перезапущен | |
| deferred | - отложена и ждет триггер |
| removed - удалена из дага после запуска | |
| Граф (Graph View) | Показывает зависимости между задачами. Вы видите, какая задача от какой зависит (например, Task A должна завершиться до Task B). |
| Диаграмма Ганта (Gantt View) | Позволяет визуально оценить время выполнения каждой задачи, найти «узкие места» (долгое ожидание в статусе queued) и понять, как задачи выполнялись параллельно. |
Отслеживание, отладка и другие возможности интерфейса
-
Где увидеть запущенные модели? Используйте путь Airflow UI → Browse → DAG Runs, чтобы посмотреть историю всех запусков (в том числе упавших).
-
Выгрузка логов: Часто возникает такая ситуация, что необходимо поделиться логами для диагностики ошибки. Это можно легко сделать в Airflow: нажмите на задачу (Task) и выберите Logs → Download для выгрузки полного файла логов.
- Остановка DAG: Если процесс завис или находится в цикле повторов, откройте Граф, нажмите на задачу и выберите Mark state as failed. Это остановит текущую задачу и предотвратит дальнейшие запуски.
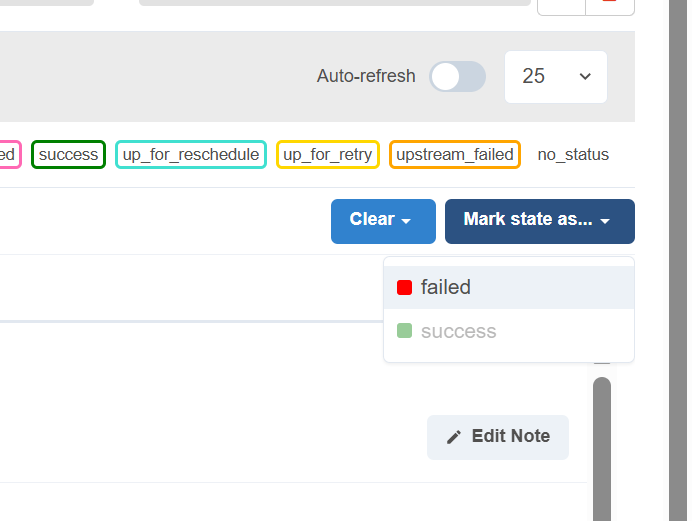
- Добавление метки к запуску. Вы можете добавить метку к конкретному запуску (DAG Run), чтобы не забыть о внесенных изменениях,например: “Внесены принудительные изменения в модель, актуализация таблицы товаров”.

 Вспомогательные DAG’и
Вспомогательные DAG’и
Внимательный пользователь системы при открытии списка всех DAG-ов системы может обратить внимание на необычное наименование некоторых из них. Например, model_104_tools. Все дело в том, что не все процессы AW BI, запускаемые Airflow, связаны только с регулярным обновлением данных.
model_N - Основной процесс синхронизации. Отвечает за сбор, преобразование и загрузку (обновление), а DAG-и c наименованием model_N_tools используются для сервисных (вспомогательных) операций. К таким можно отнести подсчет количества записей (при создании модели) или выполнение полного предпросмотра данных.
 Практический нюанс при обновлении “На основе задачи”
Практический нюанс при обновлении “На основе задачи”
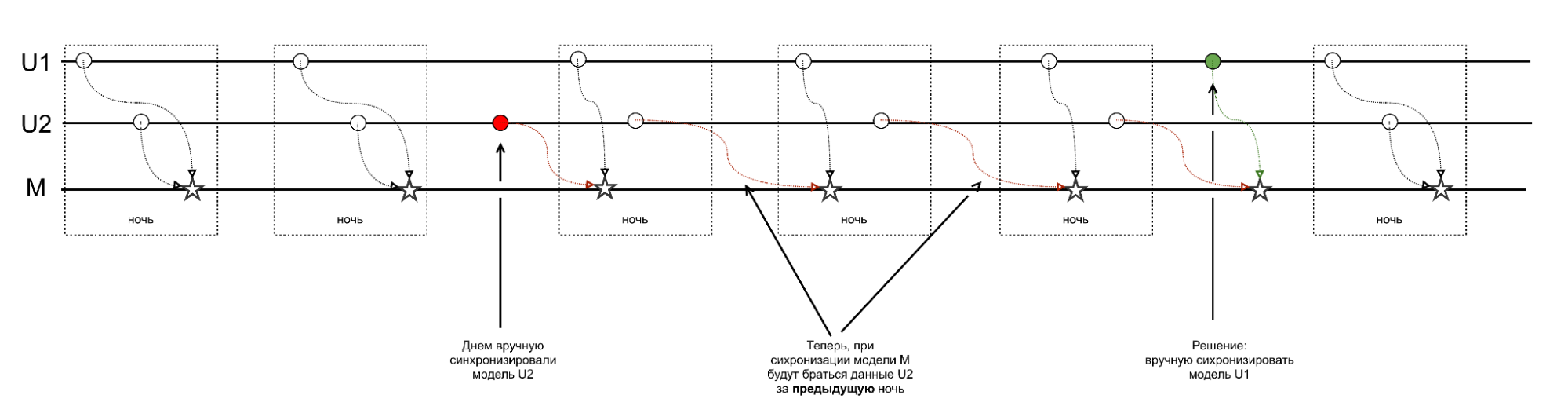
При использовании планировщика “На основе задачи” (то есть, когда одна модель зависит от успешного завершения других) может возникнуть проблема с неполной загрузкой данных, даже если в Airflow все статусы визуально выглядят как зеленые.
Если у вас есть цепочка моделей (U1 и U2 → M), и вы запускаете вручную только одну из родительских моделей (U2), то внутреннее расписание Airflow для зависимой модели (M) может “сбиться”.
- Ручной запуск U2 становится отдельным событием, но остальные события (например, плановый ночной запуск U1) не синхронизируются с ним.
- В результате, когда наступает время запуска зависимой модели M, она может стартовать, читая данные из старых версий родительских моделей (U1), что приводит к неполному набору данных в конечной модели M.
Возможное решение:
Если вы запускаете вручную одну модель из цепочки, от которой зависит другая модель, то все остальные необходимые модели-предшественники в этой цепочке также должны быть запущены вручную последовательно. Это гарантирует, что зависимая модель M будет ожидать и читать данные из актуальных версий всех своих источников. Нагляднее данный кейс можно посмотреть на схеме ниже:
Заключение
Актуализация данных - это одна из ключевых задач при работе с данными. AW BI предлагает для этого гибкий набор стратегий обновления: от простого расписания до запуска на основе событий и готовности данных.
Благодаря бесшовной интеграции с Airflow, AW BI предоставляет не просто планировщик, а мощный оркестратор, позволяющий вам:
- Управлять сложными зависимостями.
- Использовать автоматическую генерацию кода.
- Вникать в мельчайшие детали на любом этапе синхронизации через логи и визуальное представление загрузки в Airflow.
Airflow обеспечивает выполнение сложных цепочек обработки данных (DAG) в правильном порядке, с учетом зависимостей, параллельности, контроля ресурсов и логики обработки ошибок, и все это AW BI делает во многом за вас.