Кастомизация ETL-процессов с помощью написания python-кода в редакторе ETL позволяет обеспечить необходимое качество данных для их дальнейшего использования.
Подробнее здесь: Кастомизация ETL процессов с помощью python (alpha версия) - YouTube
На основе тестового набора данных, который содержит 5 распространенных low-quality кейсов, рассмотрим примеры создания функций для модификации данных.
1. Удаление дубликатов
2. Удаление символов
3. Замена символов
4. Обрезание строки
5. Разделение данных по столбцам
Описание исходного набора данных
Файл Excel c 3 таблицами (каждая на отдельном листе):
- таблица “investments” (содержит сумму, период, внешние ключи: city_id, category_id)
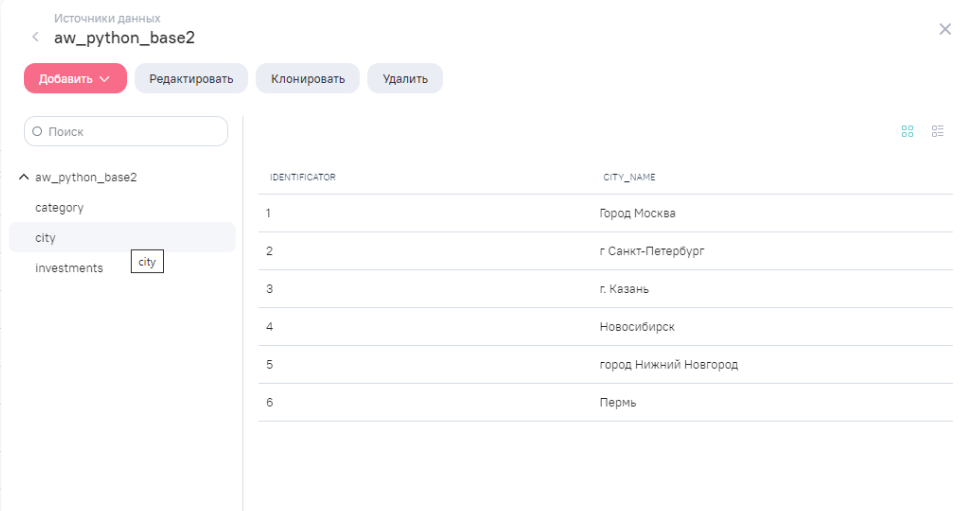
- таблица ''city" (содержит название города)
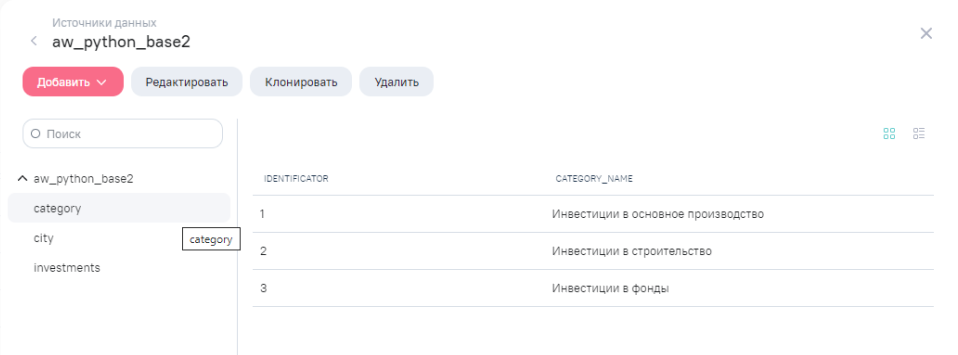
- таблица “category” (содержит вид инвестиций)
Качество данных
- таблица investments содержит дубликаты строк
- столбец “city_name” (таблица “city”) содержит избыточные символы ( “г”/“г.”/“город”/“Город”)
- столбец “sum” (таблица “investments”) содержит строковые значения “N/A”
- столбец “category_name” (таблица “category”) содержит пробелы в начале строки
- столбец “month_year” (таблица “investments”) содержит избыточную конкатенацию
Важно(!) Для устранения ошибки пункта 5 необходимо заранее, перед загрузкой в AW (Источник данных), создать в таблице-исходнике данных дополнительные столбцы для записи значений месяца и года соответственно. В текущем функционале пока отсутствует возможность создания новых столбцов непосредственно в редакторе с использованием кода.
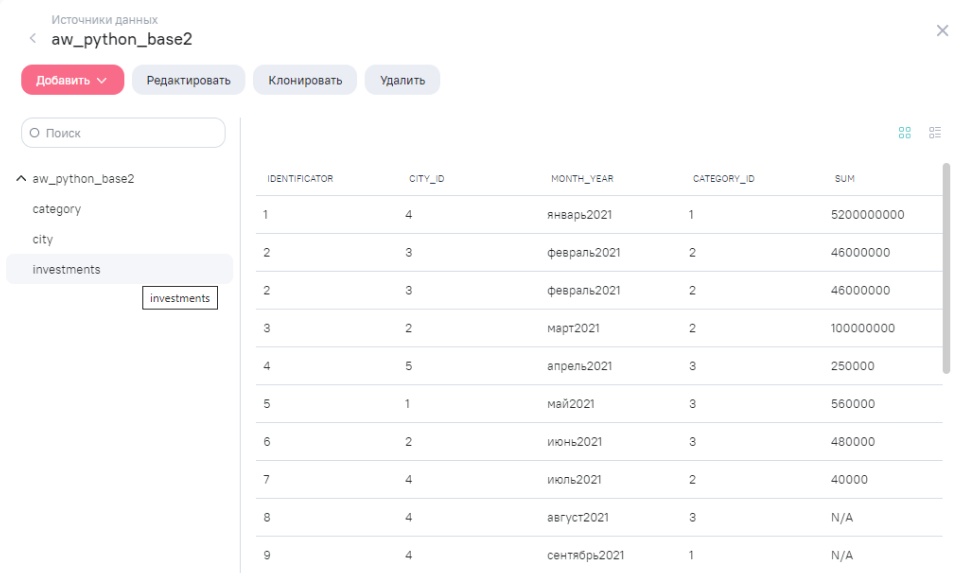
Модифицированная исходная таблица “investments” теперь содержит дополнительные столбцы “month” и “year”, которые пока не заполнены данными

Описание модели данных
Cоздаем модель данных и получаем итоговую таблицу путем настройки LEFT JOIN таблицы “investments” и таблиц “city”, “category”

Примеры функций для устранения ошибок
Для удобства чтения код для устранения каждой ошибки (даже если ошибки выявлены в пределах одной таблицы) показан в рамках отдельной функции.
Перед созданием кода импортируем необходимые библиотеки:
from pyspark.sql.functions import trim, regexp_replace, expr, \
regexp_extract, column
import re
1. Удаление дубликатов
Удаляем строки-дубли из таблицы investments:
def after_load_investments(df, app, spark, *args, **kwargs):
df = df.drop_duplicates()
return df
Итог: таблица “investments” не содержит дубликаты строк
Было:
Стало:
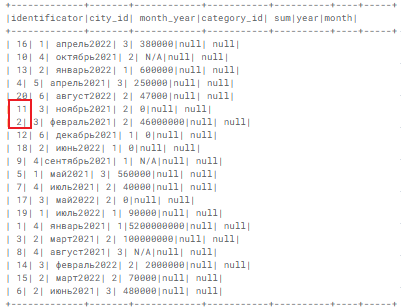
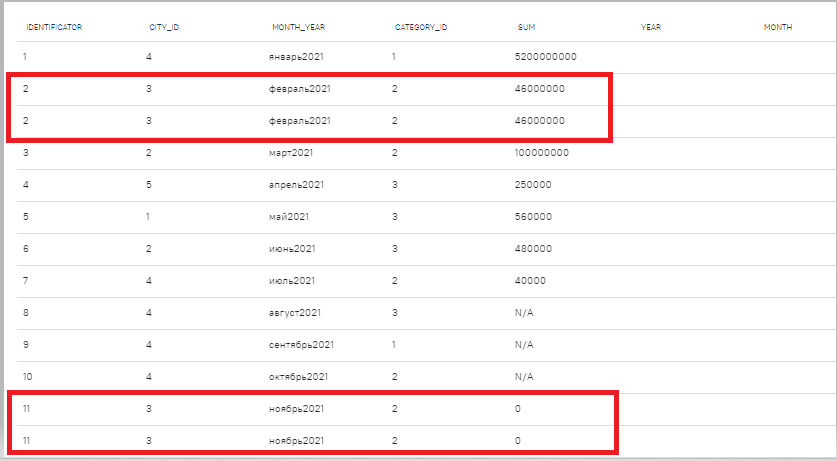
2. Удаление символов
Удаляем избыточные символы из столбца “city_name” таблицы “city”:
def after_load_city(df, app, spark, *args, **kwargs):
df = df.withColumn('city_name', regexp_replace(column('city_name'), '\.', ''))\
.withColumn('city_name', regexp_replace(column('city_name'), 'Город', ''))\
.withColumn('city_name', regexp_replace(column('city_name'), 'город', ''))\
.withColumn('city_name', regexp_replace(column('city_name'), '^\г*\Г*', ''))
return df
Итог: в столбце остались названия городов без лишних символов
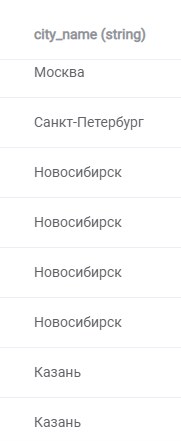
3. Замена символов
Заменяем “N/A” нулями в столбце “sum” таблицы “investments”:
def after_load_investments(df, app, spark, *args, **kwargs):
df = df.withColumn('sum', regexp_replace('sum', 'N/A', '0'))
return df
Итог: произошла корректная замена значений
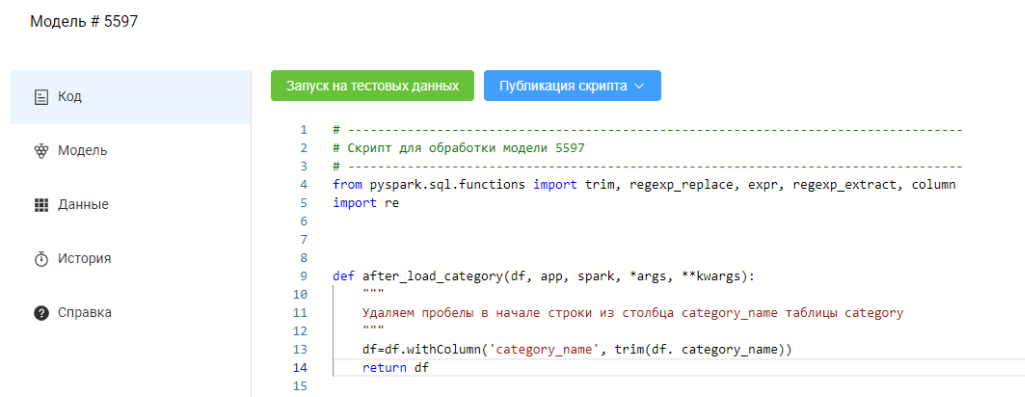
4. Обрезание строки
Удаляем пробелы в начале строки столбца “category_name” таблицы “category”:
def after_load_category(df, app, spark, *args, **kwargs):
df = df.withColumn('category_name', trim(df.category_name))
return df
Итог: пробелы удалены
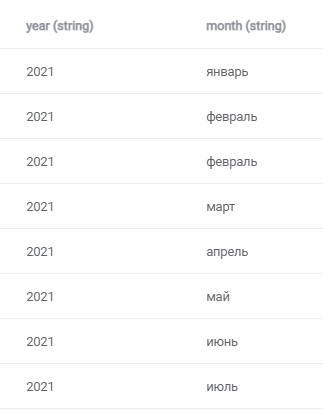
5. Разделение данных по столбцам
Разделяем данные в столбце “month_year” таблицы “investments” по заранее созданным столбцам “month” и “year”:
def after_load_investments(df, app, spark, *args, **kwargs):
df = df.withColumn('year', column('month_year'))\
.withColumn('year', regexp_replace(column('year'), '\W+', ''))
df = df.withColumn('month', column('month_year'))\
.withColumn('month', regexp_replace(column('month'), '\d+', ''))
return df
Итог: столбцы заполнены данными корректно