С переходом в облачные сервисы хранилищем данных все чаще выступают Google Spreadsheet - гугл таблицы, потихоньку вытесняя Excel.
Google Spreadsheet предлагают ролевой доступ, совместную работу, макросы и кастомизацию бизнес логики, но не предлагают локального хранения.
Перенести данные с Google Spreadsheet на свои локальные серверы и объединить их с данными других таблиц стало возможно с выходом новой версии AnalyticWorkspace 1.14 в котором добавились редактор ETL процессов и возможность добавлять виртуальные (расчетные) таблицы, что развязало руки всем BI-разработчикам.
1. Подготовка структуры данных
2. Создание, отладка и публикация скрипта
3. Запуск скрипта
Для примера будет использоваться данная таблица ФХД - Google Таблицы доступная всем на чтение у кого есть ссылка.
1. Подготовка структуры данных
Для начала необходимо создать модель, а в ней вычисляемую таблицу.
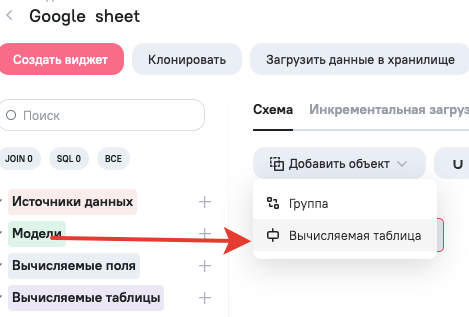
Вычисляемая или виртуальная таблица, это объект, структуру которого мы мы можем динамично создавать и содержимое наполнять, и живет этот объект только во время работы ETL процесса в Spark сессии.
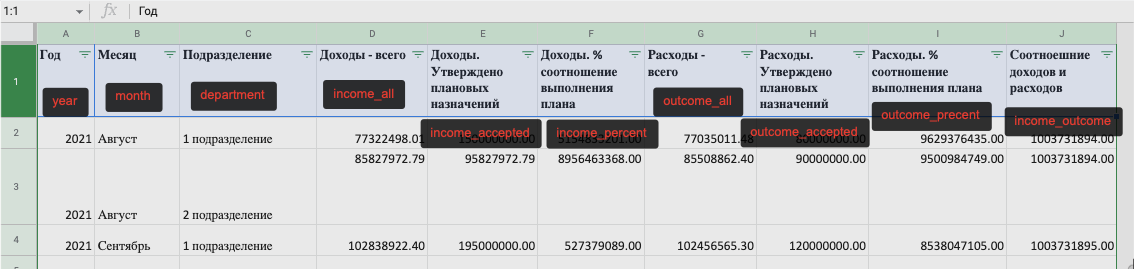
Проанализируем структуру источника и разметим будущее соответствие полей.
Описываем структуру данных в вычисляемой таблице
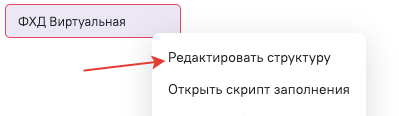
Руками задаем коды полей прописывая значение для “name” - это будут коды в данном источнике, псевдонимы зададим отдельно через редактор.
Исходя из структуры гугл таблицы видно, что числовые значения - с плавающей точкой, по-этому подойдет FloatType. “Год” - целочисленный IntegerType, “Месяц” и “Подразделение” строки StringType.
Соответствие типов в системе и типам в редакторе структуры вычисляемой таблицы:
-
Число (целое):
ByteType,ShortType, IntegerType,LongType -
Число (дробное):
FloatTpe,DoubleType,DecimalType -
Дата:
TimestampType,DateType -
Логическое:
BooleanType -
Строка:
StringType,все остальное возможное и невозможное
Необходимо обязательно перечислить требуемые типы в первой строке через запятую.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
def schema_virtual(*args, **kwargs):
return StructType([
StructField (name = 'year', dataType = IntegerType(), nullable = True),
StructField (name = 'month', dataType = StringType(), nullable = True),
StructField (name = 'department', dataType = StringType(), nullable = True),
StructField (name = 'income_all', dataType = FloatType(), nullable = True),
StructField (name = 'income_accepted', dataType = FloatType(), nullable = True),
StructField (name = 'income_percent', dataType = FloatType(), nullable = True),
StructField (name = 'outcome_all', dataType = FloatType(), nullable = True),
StructField (name = 'outcome_accepted', dataType = FloatType(), nullable = True),
StructField (name = 'outcome_precent', dataType = FloatType(), nullable = True),
StructField (name = 'income_outcome', dataType = FloatType(), nullable = True)
])
Проверяем, сохраняем

Используя in-line редактор задаем красивые псевдонимы для полей.
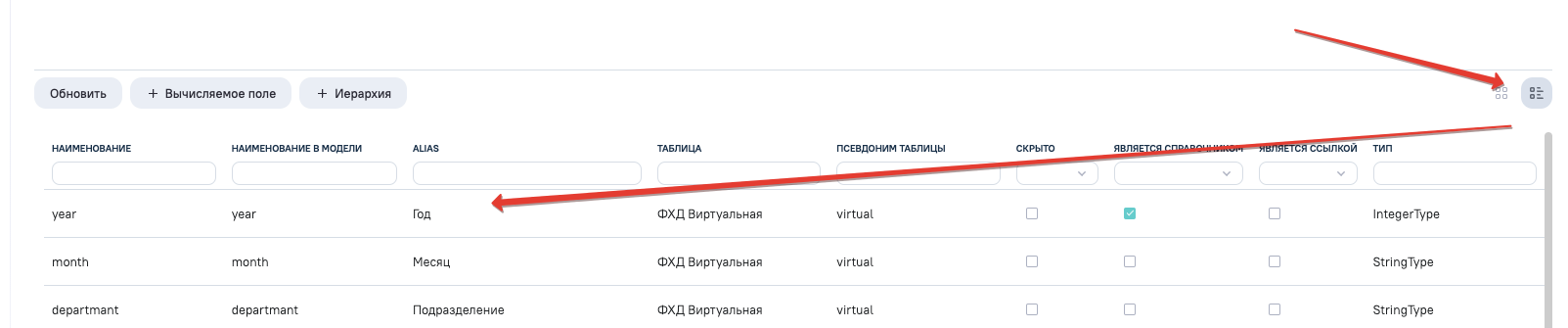
Вся подготовка завершена, теперь осталось самое простое - написать кусок кода.
Скрипт достаточно универсальный и для его переиспользования достаточно
- Задать значение переменной с ссылкой на гугл таблицу в самом начале скрипта (важно чтобы таблица была открыта на чтение)
- Задать маппинг полей модели и гугл таблицы в конце скрипта.
Важно!
Наименование метода должно содержать в себе имя модели. Его можно увидеть в описании модели*
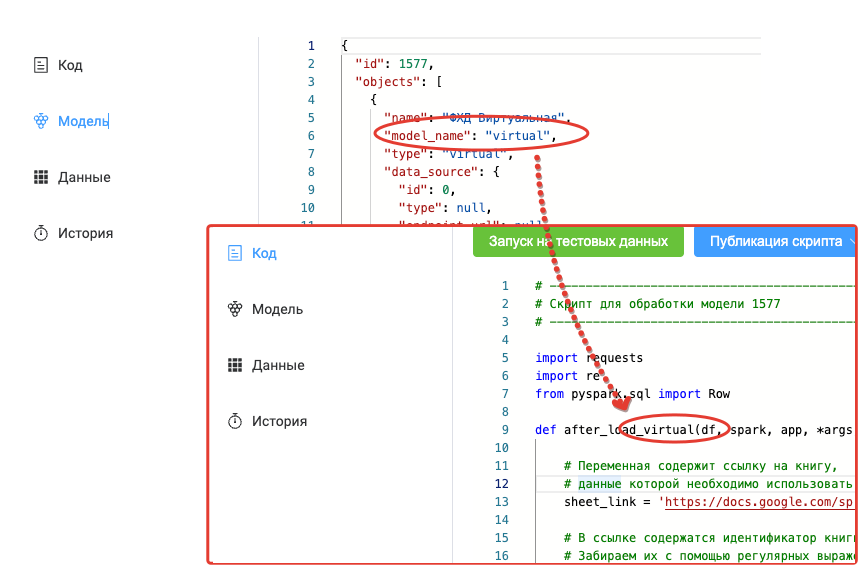
2. Создание, отладка и публикация скрипта
Собственно, сам код. Понадобятся библиотеки для работы с запросами, регулярными выражениями а также для работы со Spark-объектами.
# -----------------------------------------------------------------------------------
# Cкрипт для обработки модели 1577
# -----------------------------------------------------------------------------------
import requests
import re
from pyspark.sql import Row
def after_load_virtual(df, spark, app, *args, **kwargs):
# Переменная содержит ссылку на книгу,
# данные которой необходимо использовать
sheet_link = 'https://docs.google.com/spreadsheets/d/1laq6Mesy30xCTeR180AViDwL0Xpvo7dlxlUHRrZ1PJM/edit#gid=1905708613'
# В ссылке содержатся идентификатор книги и листа.
# Забираем их с помощью регулярных выражений.
sheet_id = re.findall('/spreadsheets/d/([a-zA-Z0-9-_]+)', sheet_link)[0]
table_id = re.findall('[#&]gid=([0-9]+)', sheet_link)[0]
# Чтобы забрать данные воспользуемся экспортом в CSV.
# Воспользуемся API гугла, встроив идентификаторы в URL.
download_file_path = f'https://docs.google.com/spreadsheets/d/{sheet_id}/export?format=csv&id={sheet_id}&gid={table_id}'
# Прокинем в лог информацию о полученной ссылке.
# Поможет, если что-то пойдет не так.
print(f'\nПолученная ссылка: {download_file_path}')
# Обратимся за данными. В случае ошибки прокинем ее в лог.
response = requests.get(download_file_path)
if not response.ok:
raise Exception(f'\nОшибка URL: {response.url} \/n {response.status_code}: {response.text}')
# Данные по умолчанию приходят в кодировке 'ISO-8859-1'.
# Меняем на привычную кодировку для корректной обработки кириллицы.
byte_array = response.text.encode(response.encoding)
decoded_text = byte_array.decode('utf-8')
# Отладочные логи, чтобы понимать какие данные в итоге получаются.
# Если данных очень много можно порезать выводя часть символов
print(f'\nПолученные данные сплошным текстом: {decoded_text[:2000]}')
# Создаем из текста массив строк
decoded_lines = decoded_text.splitlines()
print(f'\nЗаголовки: \n{decoded_lines[0]}')
# Заголовки определены вручную, как строка данных они не нужны.
# Убираем строку с заголовками.
decoded_lines.pop(0)
# Создаем массив, из которого далее будет создан dataFrame
data_frame_rows = []
# Проходим по всем строкам.
# Считаем и выводим каждую
iterator = 1
for line in decoded_lines:
print(f'{iterator}: {line}')
# Создаем из строки массив столбцов
row = line.split(',')
data_frame_rows.append(Row(
# Сопоставляем столбцы модели данных со столбцами в гугл-таблице
# Дополнительно числовые типы явно приводим в число с плавающей точкой.
year = row[0],
month = row[1],
departmant = row[2],
income_all = float(row[3]),
income_accepted = float(row[4]),
income_percent = float(row[5]),
outcome_all = float(row[6]),
outcome_accepted = float(row[7]),
outcome_precent = float(row[8]),
income_outcome = float(row[9])
))
iterator += 1
return spark.createDataFrame(data_frame_rows)
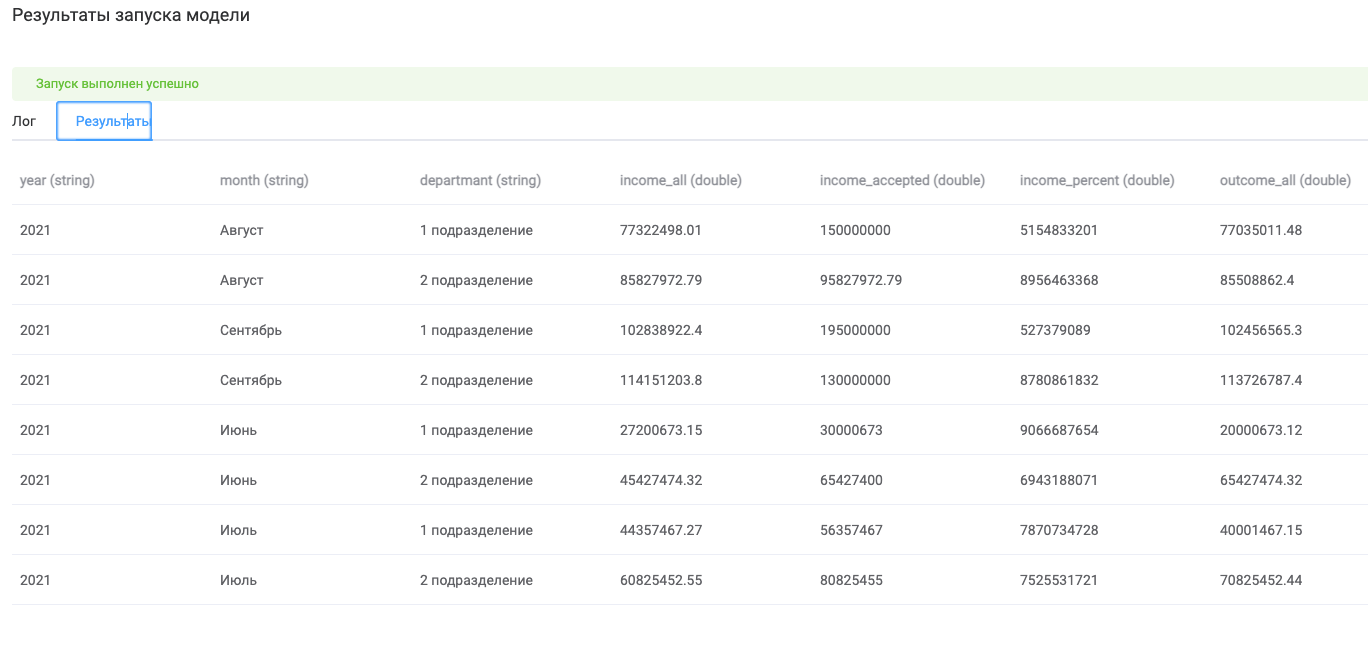
Проверить промежуточные результаты работы, почитать логи, поймать ошибки можно во время запуска на тестовых данных

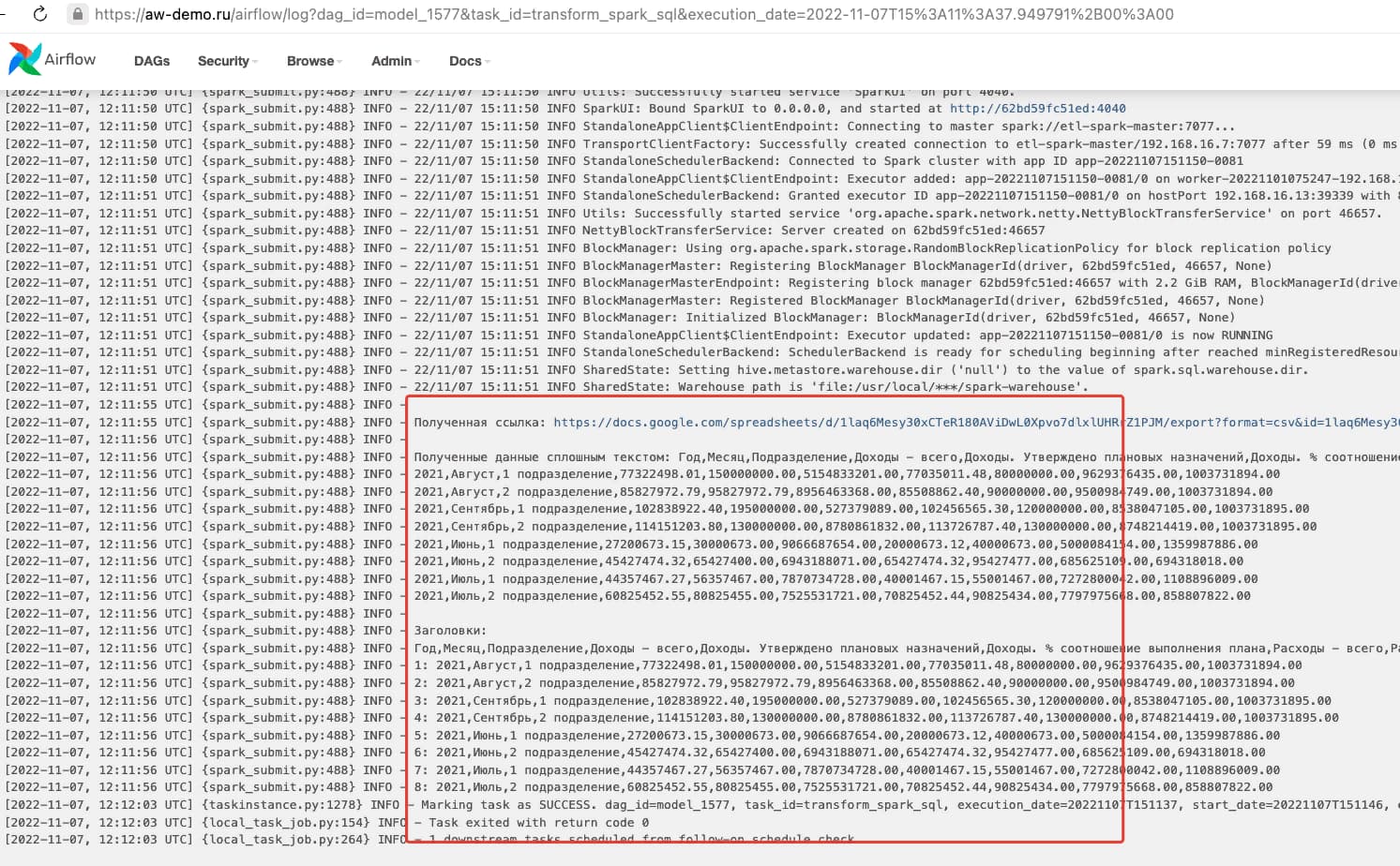
Разбросанные по коду вызовы “print” дают следующий результат во время тестовых прогонов скрипта, позволяя проводить удаленную отладку
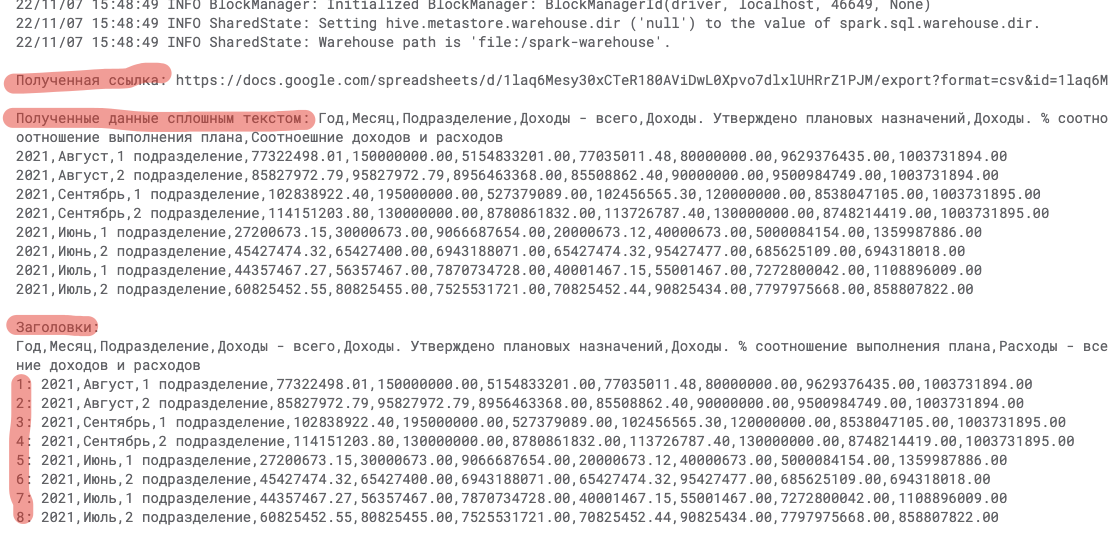
Промежуточные результаты нас устраивают
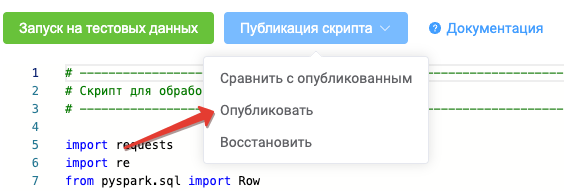
Когда все готово, для возможности запуска скрипта во время загрузки данных, скрипт необходимо опубликовать
3. Запуск скрипта
Для загрузки данных из веб сервиса в виде csv файла в вычисляемую таблицу а затем переместить данные в аналитическое хранилище необходимо нажать одну кнопку. После нажатия на “Загрузить данные в хранилище”, за ходом работы можно следить в Apache Airflow по нажатию на кнопку в правой верхней части экрана.
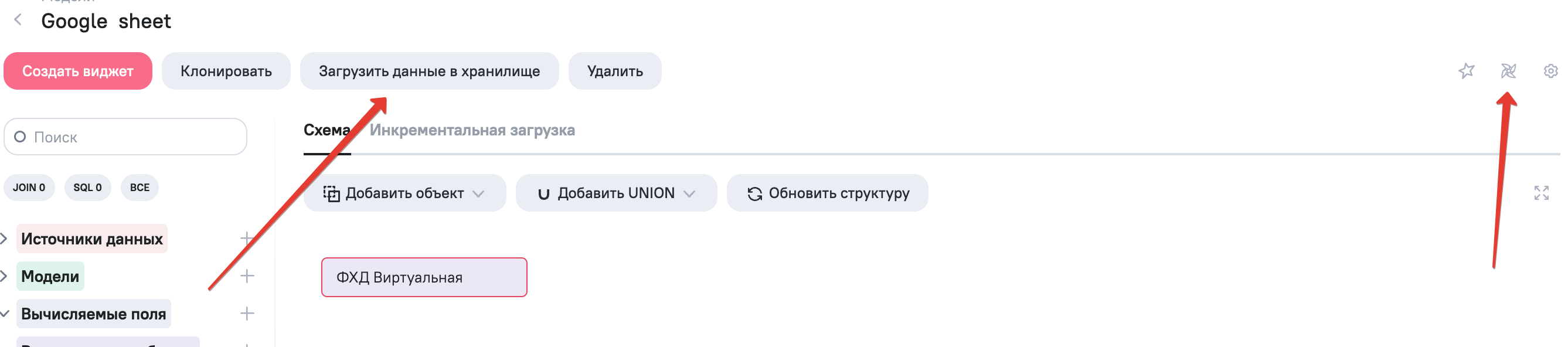
Будет осуществлен авторизованный переход в Apache Airflow и доступна панель с информацией о выполнении автосгенерированного DAG-а
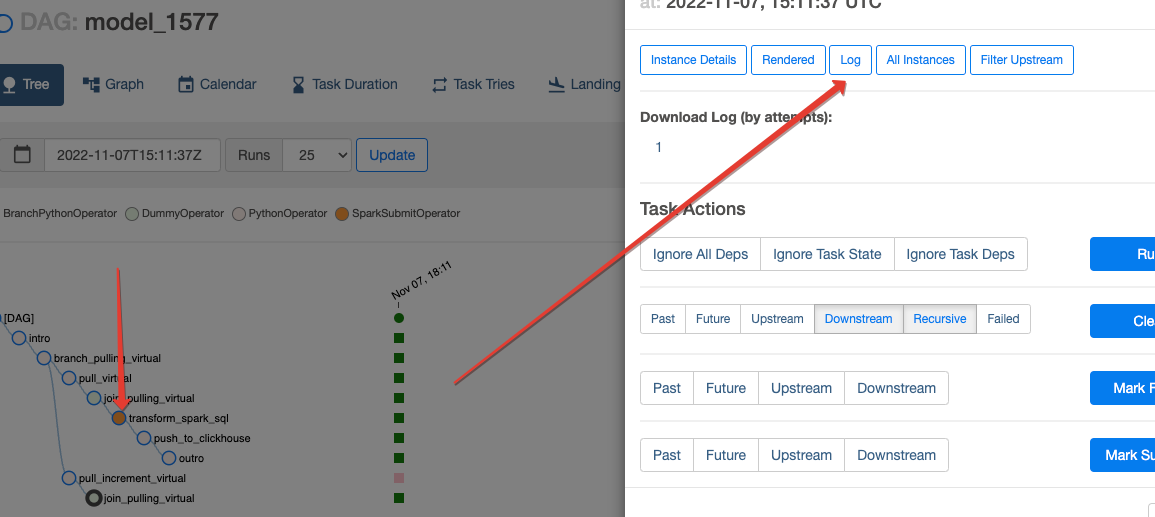
Там же можно увидеть отладочные логи во время “боевого выполнения”
Напомним, что эти данные можно объединять с другими источниками, файлами, рсубд и у вычисляемых таблиц доступен весь привычный функционал.
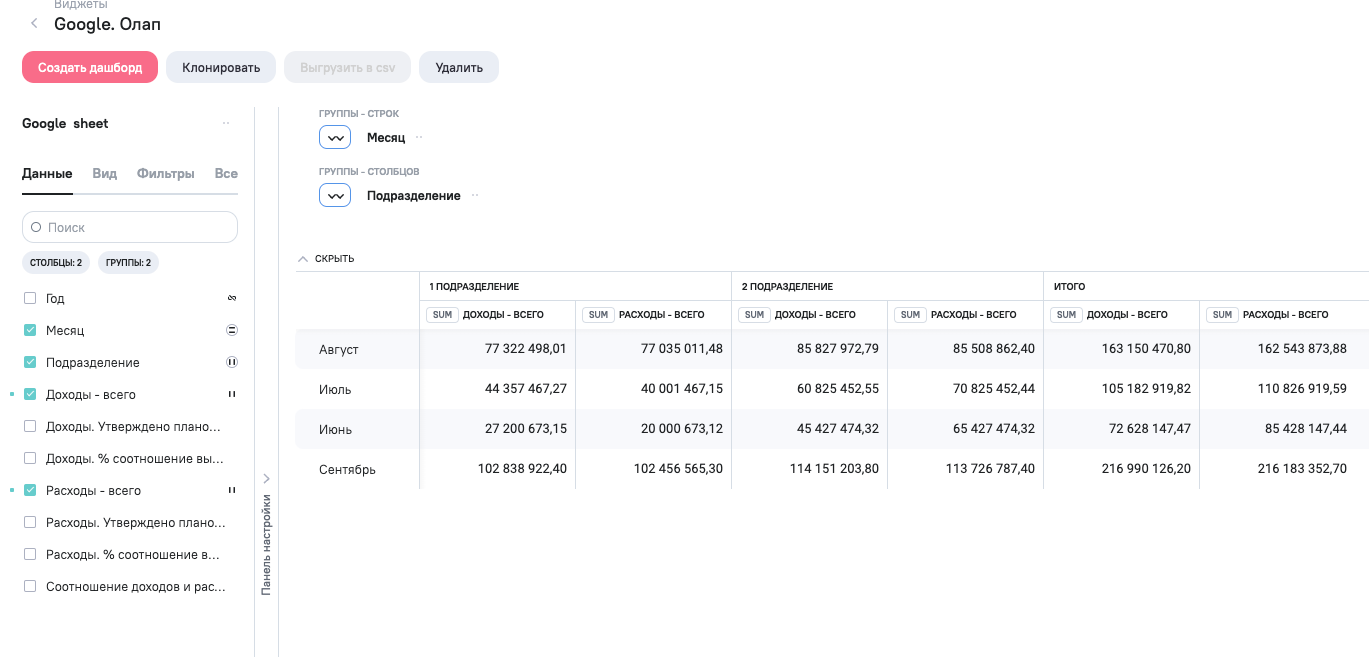
Далее создать виждет можно уже закрытыми глазами
P.S
Конечно же API у Google Spreadsheet гораздо шире. Но для быстрого получения данных и качественного анализа описанного выше метода более чем достаточно. Каждый раз будет выгружаться актуальный набор данных.