Покажем, как использовать ETL-блок “Декоратор” для выполнения самых базовых операций с таблицами данных при помощи PySpark Dataframe API.
Источник данных Candy_Salex.xlsx можно скачать по этой ссылке. Загрузите скачанный по ссылке файл в AW.
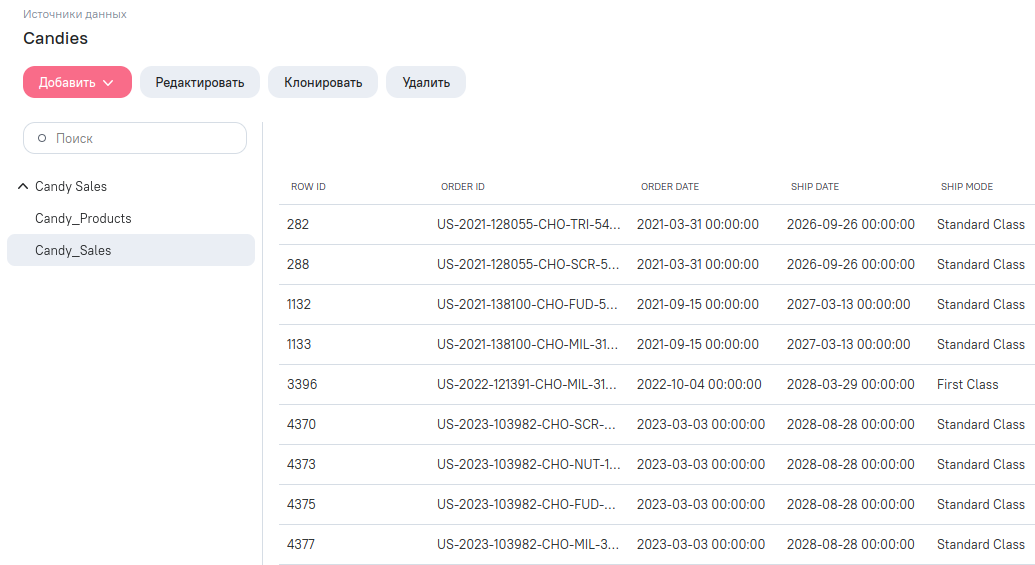
В файле есть два листа:
- данные по продуктам (Candy_Products);
- данные по продажам (Candy_Sales).
Задача будет состоять в том, чтобы получить таблицу с помесячными продажами (в деньгах и в штуках) конфет от каждой фабрики в каждом городе США.
Создайте новую логическую модель и выполните следующие действия:
- Добавьте ETL-блок “Декоратор” (Добавить объект → ETL-блок → Выберите “Декоратор”). Сразу после добавления объекта откроется правая панель с настройками блока - пока просто закройте её.
- Добавьте в модель источник данных Candies перетащите таблицы Candy_Products и Candy_Sales внутрь ETL-блока.
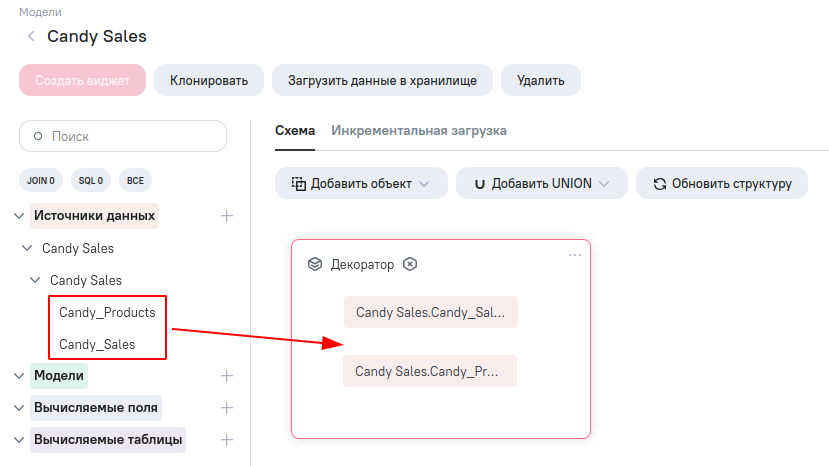
Перейдем к настройке ETL-блока. Нажмите три точки и в правой панели заполните поля с названиями функций, которые будут использоваться для получения схемы и данных блока
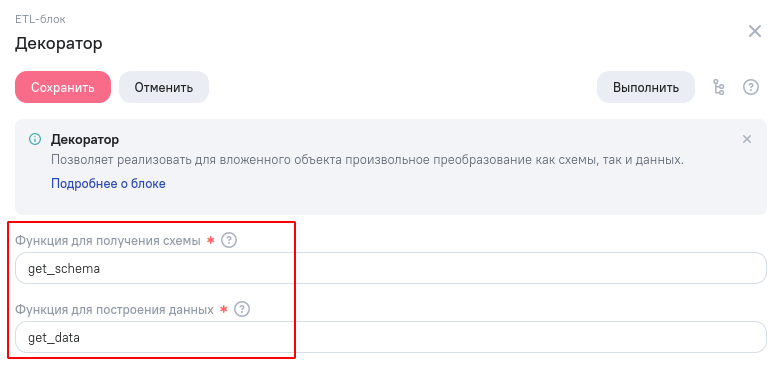
Схема блока - это структура порождаемой блоком таблицы с данными: перечисление столбцов таблицы с указанием их типов. А данные блока - это датафрейм со строками таблицы.
Перейдем к настройке функций. Сохраните форму с параметрами блока и затем откройте ETL-редактор модели. Для этого, нажмите в правом верхнем углу редактора модели соответствующую пиктограмму
Опишем структуру порождаемой блоком таблицы. Для этого в ETL редакторе создадим функцию get_schema (название функции может быть произвольным, но должно совпадать с тем, что указано в настройках блока “Декоратор”).
Добавим в самом начале скрипта импорт необходимых имен типов из модуля pyspark.sql.types и вернем из функции структуру StructType как указано в примере ниже.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
def get_schema():
"""
Возвращает схему данных блока
"""
return StructType(fields=[
StructField('year_month', StringType(), True),
StructField('factory', StringType(), True),
StructField('city', StringType(), True),
StructField('sales', FloatType(), True),
StructField('units', IntegerType(), True)
])
Подробнее об использовании StructType можно узнать из официальной документации PySpark.
Официальная документация по всем возможным типам данных Spark приведена здесь.
Перейдем к описанию функции получения данных. Добавляем в скрипт функцию get_data (опять же, название функции может быть произвольным, но должно совпадать с тем, что указано в настройках блока “Декоратор”).
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
Пока мы описываем процедуру получения данных блока, возвращать из функции ничего не будем. Добавим оператор return в самом конце.
Для начала, нам нужно получить доступ к вложенным в блок таблицам. Для этого, воспользуемся параметром функции dfs.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
Здесь, названия 'candy' и candy_products - это присвоенные системой имена вложенных объектов. У вас они могут называться по-другому. Чтобы узнать имена вложенных таблиц, откройте параметры блока и нажмите на пиктограмму “Структура вложенных объектов” в правом верхнем углу.
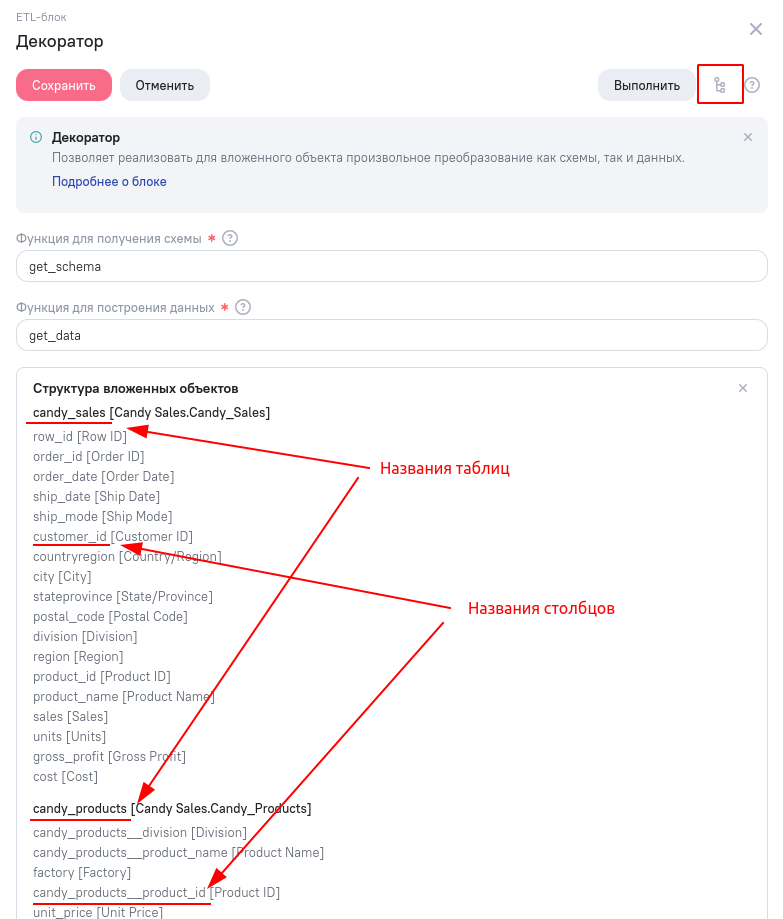
Здесь же, можно узнать, как будут называться столбцы вложенных таблиц. Необходимо учитывать, что при добавлении в модель данных нескольких таблиц с одинаковыми названиями столбцов, AW может для второго и последующих таких столбцов сгенерировать уникальное имя. Всегда уточняйте названия столбцов при обращении к ним.
Итак, убедимся, что мы получили из dfs правильные таблицы. Для этого воспользуемся оператором print.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
print(df_products)
Нажмите зеленую кнопку Запуск на тестовых данных для запуска скрипта на выполнение и дождитесь окончания его работы.
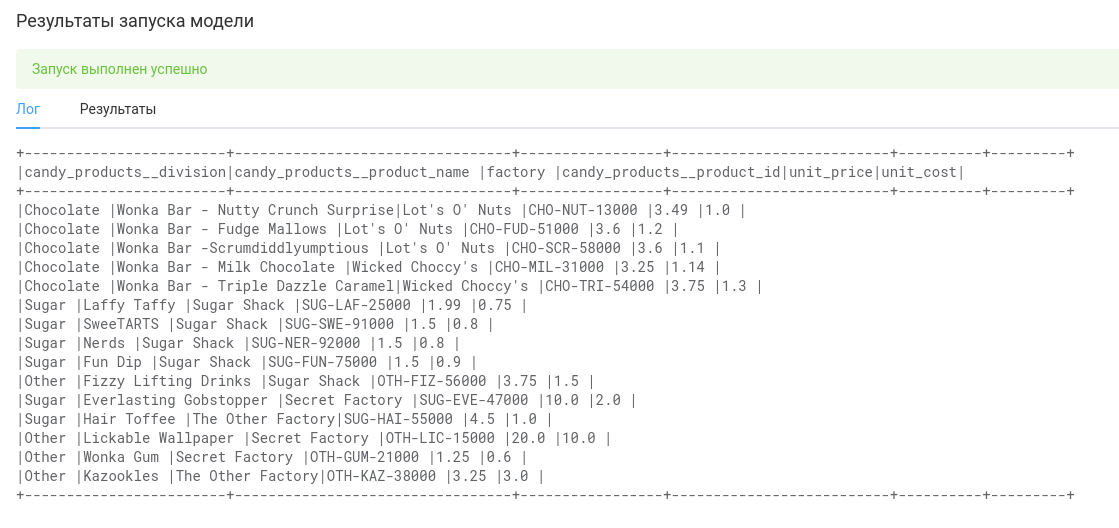
Мы видим, что система распечатала данные, которые мы и ожидали увидеть (т.е., содержимое таблицы Candy_Products).
Согласно условию задачи нам необходимо отфильтровать продаже по региону “United States”. Для этого воспользуемся методом датафрейма filter.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
print(df_sales)
Обратите внимание, что результат выполнения метода filter не изменяет текущий датафрейм, а создает новый. Поэтому, чтобы продолжить с ним работу, нам нужно сохранить результат filter в какой-либо переменной. Например, для этого можно воспользоваться тем же именем df_sales.
Запустив скрипт на выполнение, убеждаемся что ошибок нет и команда фильтрации работает ожидаемым образом.
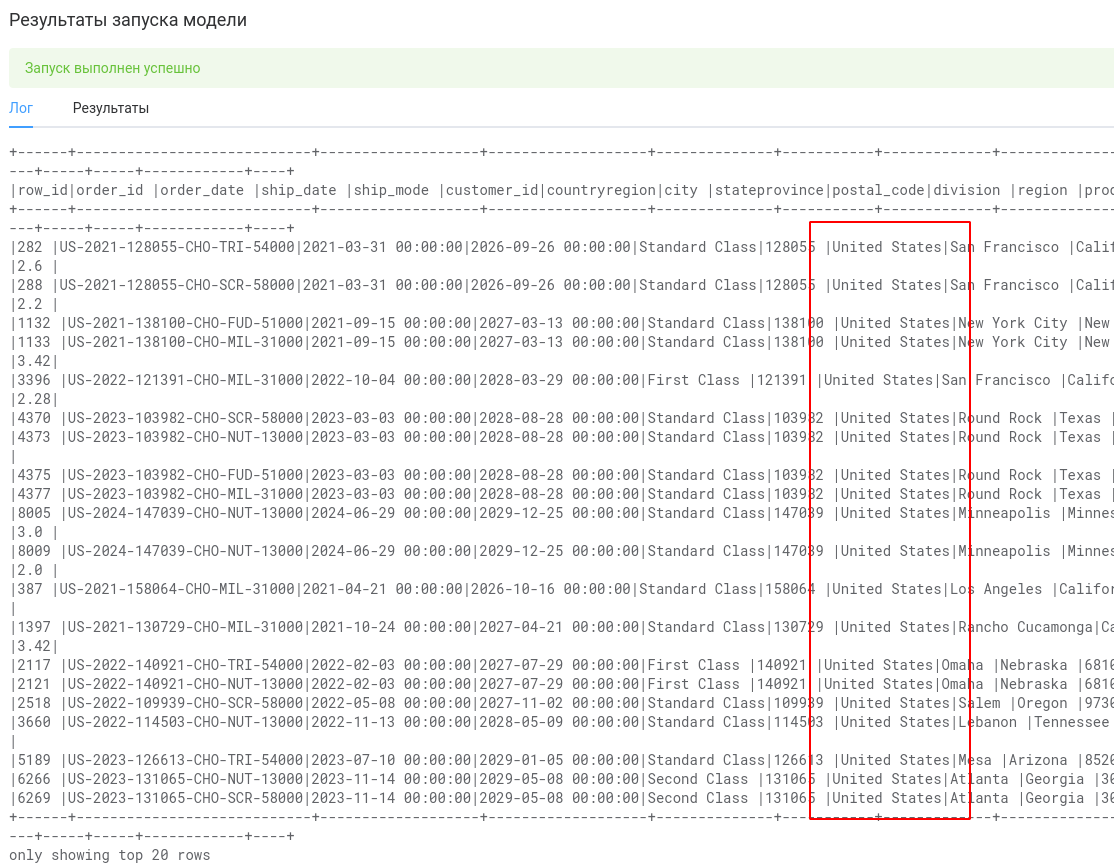
Далее, по заданию нам нужно получить датафрейм, в котором появится дополнительный столбец factory, который присутствует только в таблице Candy_Products (датафрейм df_products).
Для этого выполняем join двух датафреймов.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
print(df)
Опять таки, обратите внимание, что после вызова join создастся новый датафрейм, который нужно “сохранить” в отдельной переменной. В нашем примере, такой новый датафрейм будет называться df (имя можно выбрать любым, главное использовать выбранное значение до конца работы функции).
Распечатка полученного датафрейма занимает много места на экране из-за большого количества столбцов. Но нам нужны только некоторые из них. Поэтому, воспользуемся методом select для отбора только нужных нам полей.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
print(df)
return
Вот теперь работать с df будет удобнее.
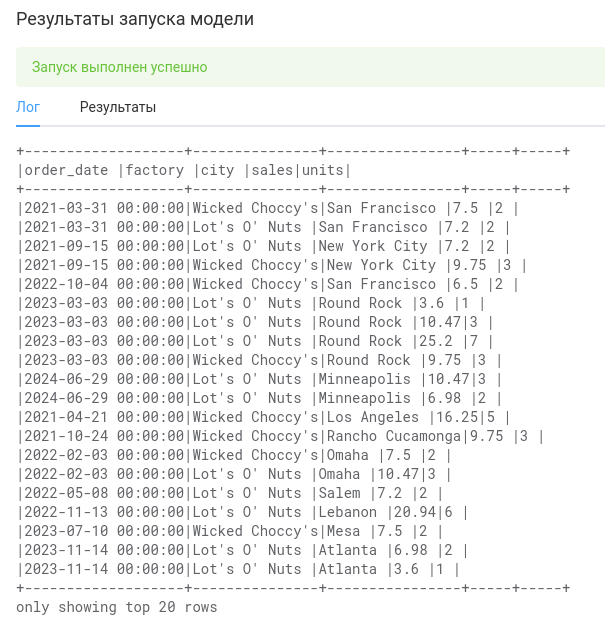
Далее, преобразуем дату order_date в строку year_month (чтобы там хранились значения вида 2024-09). Для этого нам понадобится метод withColumn, который добавляет или заменяет указанный столбец датафрейма на указанное значение.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
df = df.withColumn('year_month', date_trunc('month', df.order_date))
df = df.withColumn('year_month', cast('string', df.year_month))
df = df.withColumn('year_month', substring(df.year_month, 0, 7))
print(df)
Обратите внимание, что для выполнения операций преобразования нам понадобятся три функции date_trunc, cast и substring (приведение даты в первое число месяца, преобразование даты к строке и взятие той части строки, которая отвечает за год и месяц). Для их использования к блоку с импортами типов, добавим ещё и импорт данных функций.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql.functions import date_trunc, cast, substring
Такое преобразование столбца с датой можно было бы сделать разными (и более оптимальными способами), но для академических целей оно приводится именно в эти три шага. Тут видно, как применяются функции к столбцам и как происходит приведение значений столбца в нужный тип данных.
Далее, сгруппируем полученный датафрейм, использовав метод groupBy.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
df = df.withColumn('year_month', date_trunc('month', df.order_date))
df = df.withColumn('year_month', cast('string', df.year_month))
df = df.withColumn('year_month', substring(df.year_month, 0, 7))
df = df.groupBy([df.year_month, df.factory, df.city]).agg(
sum(df.sales),
sum(df.units)
)
print(df)
Для подсчета агрегатов (см. параметры вызова .agg(...) нам понадобится функция sum, которую мы тоже должны импортировать из pyspark.sql.functions.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql.functions import date_trunc, cast, substring, sum
Запустим скрипт на выполнение.
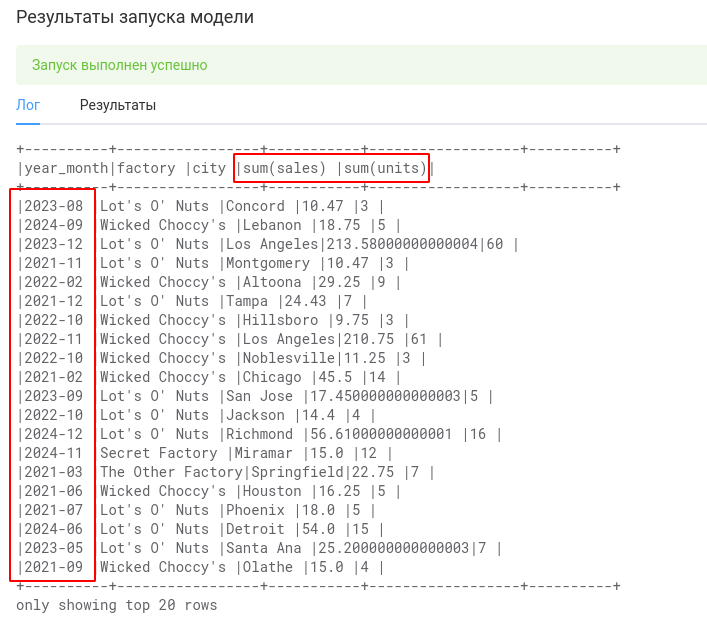
Видим, что преобразование order_date в year_month прошло успешно. Однако, после группировки столбцы с агрегатами стали называться не так, как мы хотели. Для переименования столбцов воспользуемся методом столбца alias
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
df = df.withColumn('year_month', date_trunc('month', df.order_date))
df = df.withColumn('year_month', cast('string', df.year_month))
df = df.withColumn('year_month', substring(df.year_month, 0, 7))
df = df.groupBy([df.year_month, df.factory, df.city]).agg(
sum(df.sales).alias('sales'),
sum(df.units).alias('units')
)
print(df)
На скриншоте последнего запуска видно, что после выполнения суммирования у нас по некоторым значениям столбца sales произошло превышение точности вычислений и появились некрасивые остатки в незначимых знаках после запятой. Нам надо применить округление результатов.
Это можно сделать через withColumn (применив функцию round из pyspark.sql.functions), однако с академической целью покажем, как над датафреймом можно выполнить произвольный sql запрос.
Для этого, сначала зарегистрируем df в пространстве имен SQL-таблиц спарка (см. createOrReplaceTempView, а затем выполним SQL запрос с round.
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
df = df.withColumn('year_month', date_trunc('month', df.order_date))
df = df.withColumn('year_month', cast('string', df.year_month))
df = df.withColumn('year_month', substring(df.year_month, 0, 7))
df = df.groupBy([df.year_month, df.factory, df.city]).agg(
sum(df.sales).alias('sales'),
sum(df.units).alias('units')
)
df.createOrReplaceTempView('sales_groups')
df = spark.sql('select year_month, factory, city, round(sales, 2) as sales, units from sales_groups')
print(df)
print(df.schema)
Аналогично предупреждениям выше, вызов spark.sql создает новый датафрейм, и чтобы продолжить его использовать, нужно сохранить результат вызова метода в отдельную переменную (нам подойдет то же имя, что и было раньше, т.е. df).
Вот теперь всё выглядит хорошо. Заодно, посмотрим на схему данных после всех преобразований - распечатаем её через print(df.schema).
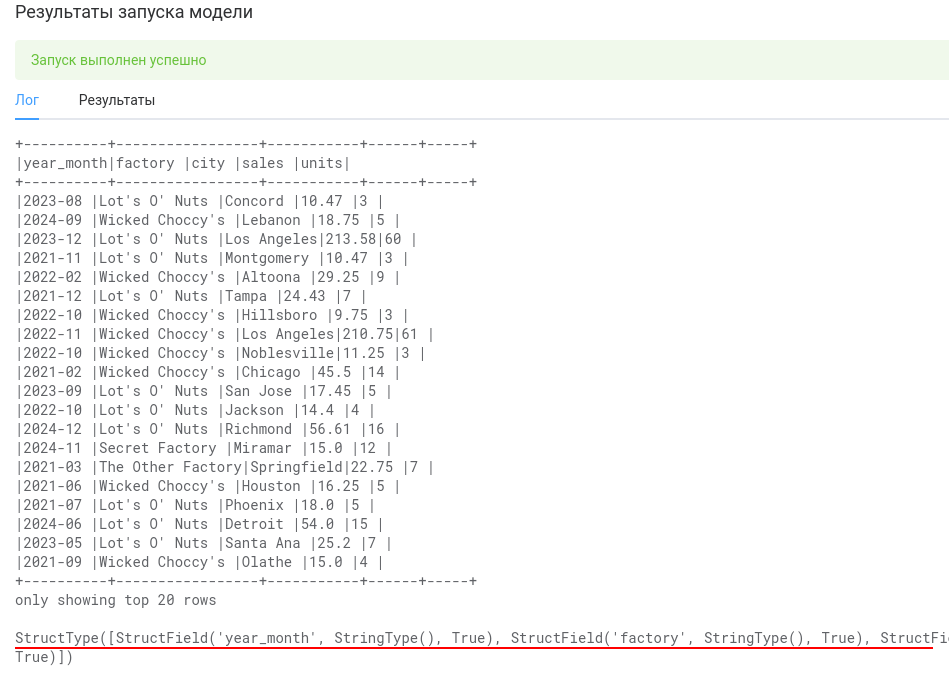
В самом начале мы указывали схему данных в функции get_schema. Обратите внимание, то эта функция только декларирует для AW, какие будут столбцы в датарейме блока. Но эта декларация может отличаться от того, что в итоге получится в результате ваших преобразований. Это может привести к ошибкам на этапе обработки данных. Поэтому, вам нужно убедиться, что продекларированная и реальная схемы данных совпадают.
Ну и, в завершение, отсортируем результаты и вернем полученный датафрейм df из функции. Для сортировки месяцев по убыванию нам понадобится функция desc. Итоговый скрипт будет выглядеть так.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
from pyspark.sql.functions import date_trunc, cast, substring, sum, desc
def get_schema():
"""
Возвращает схему данных блока
"""
return StructType(fields=[
StructField('year_month', StringField(), True),
StructField('factory', StringField(), True),
StructField('city', StringField(), True),
StructField('sales', FloatType(), True),
StructField('units', IntegerType(), True)
])
def get_data(dfs, spark):
"""
Возвращает данные блока
"""
df_sales = dfs['candy_sales']
df_products = dfs['candy_products']
df_sales = df_sales.filter(df_sales.countryregion == 'United States')
df = df_sales.join(df_products, df_sales.product_id == df_products.candy_products__product_id, how='left')
df = df.select('order_date', 'factory', 'city', 'sales', 'units')
df = df.withColumn('year_month', date_trunc('month', df.order_date))
df = df.withColumn('year_month', cast('string', df.year_month))
df = df.withColumn('year_month', substring(df.year_month, 0, 7))
df = df.groupBy([df.year_month, df.factory, df.city]).agg(
sum(df.sales).alias('sales'),
sum(df.units).alias('units')
)
df.createOrReplaceTempView('sales_groups')
df = spark.sql('select year_month, factory, city, round(sales, 2) as sales, units from sales_groups')
df = df.orderBy(desc(df.year_month), df.city)
return df
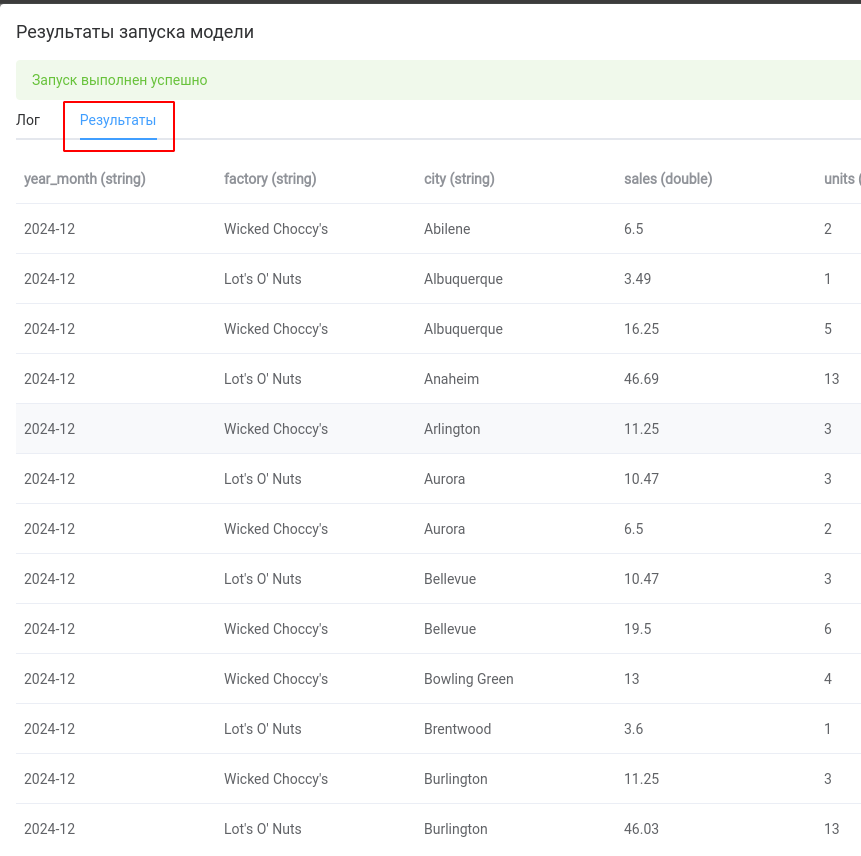
На вкладке “Результаты” можем ознакомиться с результатами работы скрипта.
.
Публикуем скрипт.
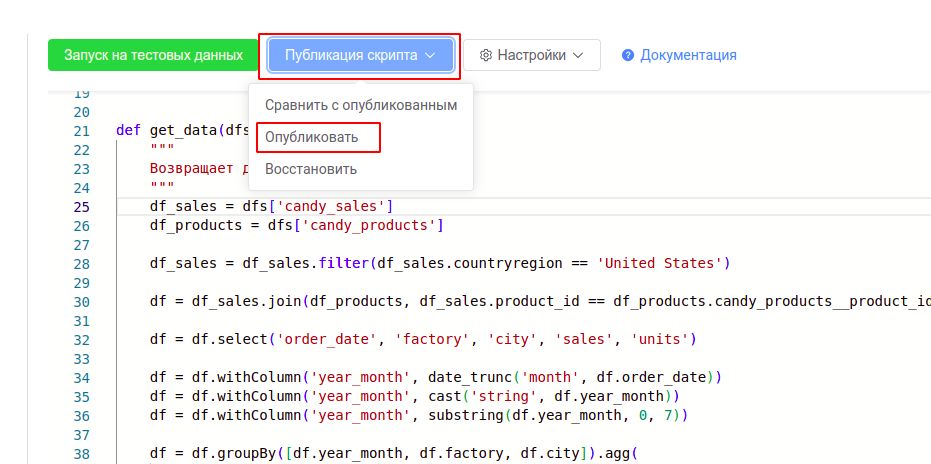
Возвращаемся в редактор модели данных, открываем параметры ETL-блока и нажимаем кнопку “Выполнить”, чтобы убедиться, что скрипт опубликовался.
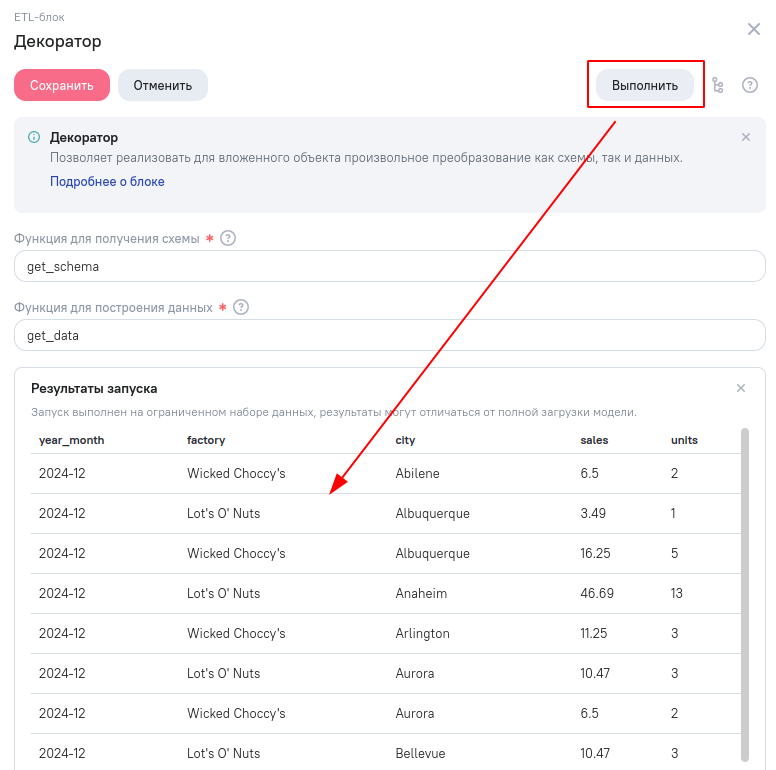
Всё! Теперь сохраняем ETL-блок (и, если нужно обновляем структуру и данные превью в редакторе модели).