При работе в системе у пользователя может возникнуть потребность загружать данные напрямую из удаленных ресурсов, а также передавать web-сервисам данные для записи, информировать через мессенджеры.
Так как работа с сервисами достаточно разносторонняя, то на данный момент было решено дать возможность работать с ними не через соединения в системе, а через редактор ETL, который позволяет реализовать разнообразную логику, оперируя нужными методами в каждой из точек расширения процесса трансформации модели данных. Подробнее здесь: Справка
Рассмотрим несколько примеров
1. Получение данных в формате JSON
2. Получение данных в формате CSV
3. Создание записи в БД удаленного web-сервиса
4. Отправка данных в чат Telegram
Примеры 1 и 2 позволяют увидеть, что обработка входящих данных различных форматов имеет свои особенности, поэтому эти пункты выделены отдельно.
1. Получение данных в формате JSON
Задача: необходимо получить данные в json формате с web-сервиса и использовать их в общем ETL процессе. Набор данных: ‘https://api.covidtracking.com/v1/us/daily.json’
Алгоритм решения:
- Проанализируем исходный набор данных и определим заголовки столбцов:
['at', 'positive', 'hospitalizedcurrently', 'hospitalizedcumulative',
'onventilatorcurrently', 'onventilatorcumulative']
-
В системе создадим источник данных на основе таблицы Excel, содержащей указанные заголовки столбцов, чтобы сформировать модель данных куда данные будут записаны. В будущем будет возможность создавать виртуальные таблицы автоматически, а пока мы сделаем это вручную. Таблица пока не заполнена данными.
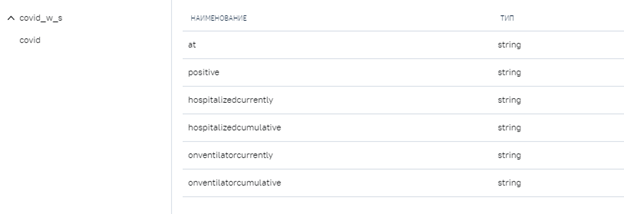
-
Создадим модель данных на основе источника.
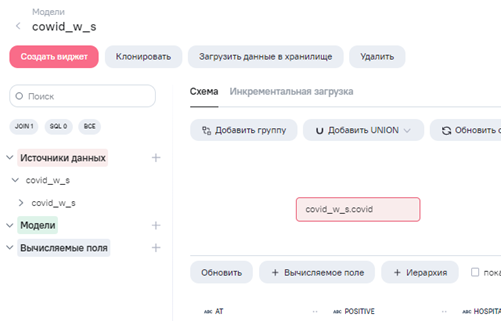
-
Импортируем необходимые библиотеки:
import requests
import datetime
from pyspark.sql import Row
- Добавим функцию, по итогам выполнения которой, в таблицу источника будут записаны данные:
def after_load_covid(df, spark, app, *args, **kwargs):
r = requests.get('https://api.covidtracking.com/v1/us/daily.json')
if not r.ok:
raise Exception(f'Ошибка GET {r.url}. HTTP {r.status_code}: {r.text}')
#Создадим список, который послужит основной для создания DataFrame
rows = []
for line in r.json():
rows.append(Row(
at=datetime.datetime.strptime(str(line['date']), '%Y%m%d'),
positive=line['positive'],
hospitalizedcurrently=line['hospitalizedCurrently'],
hospitalizedcumulative=line['hospitalizedCumulative'],
onventilatorcurrently=line['onVentilatorCurrently'],
onventilatorcumulative=line['onVentilatorCumulative'],
))
return spark.createDataFrame(rows)
Важно!
Наименование метода должно содержать в себе имя модели. Его можно увидеть в описании модели:
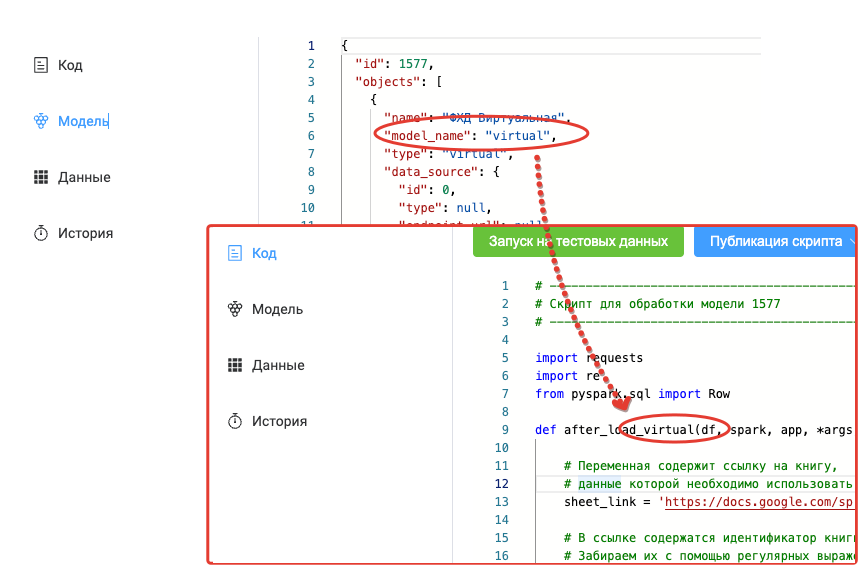
В итоге, данные успешно записаны в DataFrame:
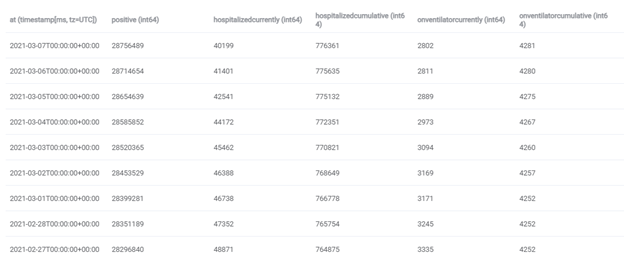
2. Получение данных в формате CSV
Задача: необходимо получить данные в csv формате с web-сервиса и использовать их в общем ETL процессе.
Набор данных: ‘https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-csv.csv’
Алгоритм решения пошагово идентичен примеру 1, однако на уровне кода обработка полученных данных имеет ряд особенностей, что связано с форматом загружаемых данных:
- Проанализируем исходный набор данных и определим заголовки столбцов:
['Year', 'Industry_aggregation_NZSIOC', 'Industry_code_NZSIOC',
'Industry_name_NZSIOC', 'Units', 'Variable_code', 'Variable_name',
'Variable_category', 'Value', 'Industry_code_ANZSIC06']
-
В системе создадим источник данных на основе таблицы Excel, содержащий указанные заголовки столбцов. Таблица пока не заполнена данными.
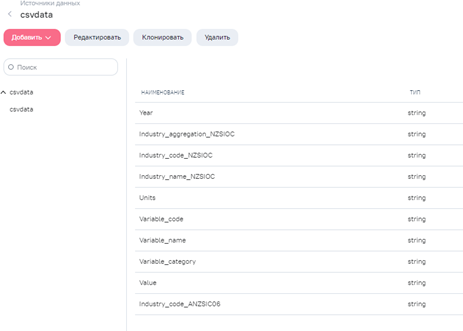
-
Создадим модель данных на основе источника:
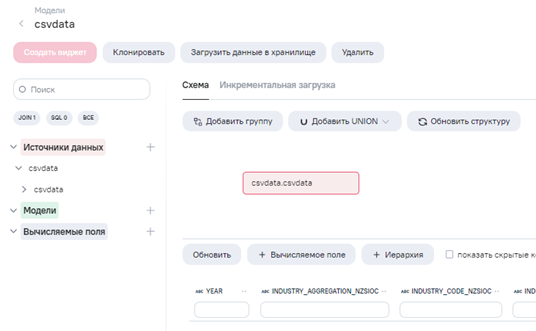
-
Импортируем необходимые библиотеки:
import requests
import csv
- Добавим функцию, по итогам выполнения которой, в таблицу источника будут записаны данные:
def after_load_csvdata(df, spark, app, *args, **kwargs):
r = requests.get('https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-csv.csv')
#Преобразуем ответ от сервиса в список списков (матрицу), который потребуется для создания DataFrame
lines = r.text.splitlines()
csv_data = csv.reader(lines)
data = []
for row in csv_data:
data.append(row)
#Удалим самый первый список с заголовками из набора списков,
чтобы не дублировать их в итоговом DataFrame
del data[0]
columns = ['Year', 'Industry_aggregation_NZSIOC', 'Industry_code_NZSIOC',
'Industry_name_NZSIOC', 'Units', 'Variable_code', 'Variable_name',
'Variable_category', 'Value', 'Industry_code_ANZSIC06']
return spark.createDataFrame(data,columns)
В итоге, данные успешно записаны в DataFrame:
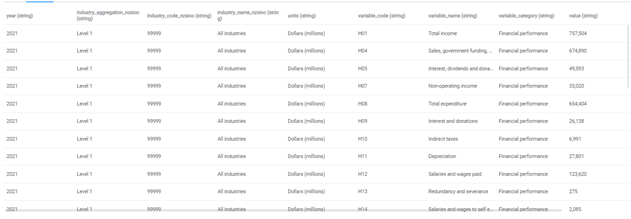
3. Создание записи в БД удаленного web-сервиса
Задача: необходимо передать данные для записи (‘name’, ‘email’, ‘password’) стороннему web-сервису Users (bugred.ru), чтобы создать новых пользователей.
Алгоритм решения:
- В системе модель данных содержит таблицу пользователей со столбцами ‘name’, ‘email’:
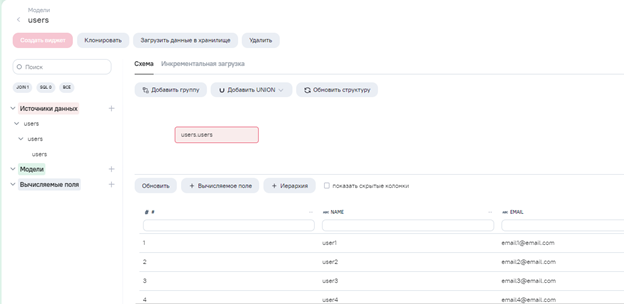
- После загрузки данных в модель нам необходимо в редакторе кода написать POST запрос. Импортируем необходимые библиотеки:
import requests
- Далее напишем функцию, которая, используя данные DataFrame в качестве параметров, направляет POST запрос на создание пользователя:
def after_load_users(df, spark, app, *args, **kwargs):
#Помещаем каждый столбец в список с помощью lambda-функции
user_name_list = df.rdd.map(lambda x: x[1]).collect()
user_email_list = df.rdd.map(lambda x: x[2]).collect()
#В качестве параметров указываем первый элемент из созданных списков
и необходимый пароль
param = {'email': user_email_list[1], 'name': user_name_list[1], 'password': '123' }
#Создаем POST запрос, в котором указываем url и параметры запроса
resp = requests.post('http://users.bugred.ru/tasks/rest/doregister', data=param)
print(resp.text)
return df
Список имен
![]()
Список email
![]()
В итоге, на удаленном ресурсе с помощью web-сервиса создан пользователь с указанными параметрами:

В нашем примере тестовый сервис не позволяет направлять запросы из цикла.
В случае работы с другими web-сервисами создание записей происходит в цикле, например:
for i in range(len(user_name_list)):
param = {'name': user_name_list[i]}
resp = requests.post('url', data=param)
4. Отправка данных в чат Telegram
Задача: направить пользователю сообщение через TelegramBot после обработки данных.
Алгоритм решения:
-
В системе AW создана модель данных, произведена запись данных в DataFrame (Ранее рассмотренный пример: 2. Получение данных в формате CSV и запись их в DataFrame).
-
Перейдем в редактор, импорт дополнительных библиотек, кроме “Requests”, не требуется. Нам необходимо создать POST запрос и указать его параметры, используя token бота, метод (отправка текстового сообщения), содержание сообщения, chat_id (ссылка на общий или индивидуальный чат бота с пользователем). Поместим код в функцию, выполняемую в точке расширения ‘after_all()’:
def after_all(df, spark, app, *args, **kwargs):
#Создаем POST запрос с параметрами 'method', 'chat_id', 'text' для отправки с помощью TelegramBot
token='****************************************************************'
url = 'https://api.telegram.org/bot'
url += token
method = url + '/sendMessage'
r = requests.post(method, data={'chat_id': **********, 'text': 'Данные из стороннего сервиса загружены'})
return df
После загрузки данных в Dataframe Telegram-бот направил пользователю сообщение:
