Для транспонирования таблицы в SQL существуют операторы PIVOT и UNPIVOT. Рассмотрим их использование на практическом примере.
Лучше всего воспроизвести данный пример самостоятельно, чтобы понять принцип работы PIVOT и UNPIVOT. Затем вы сможете применять этот подход в реальных задачах независимо от количества столбцов и тематики данных. Тренировочную таблицу можно скопировать ниже и вставить, например, в .xlsx.
| Показатель | Магазин1 | Магазин2 | Магазин3 |
|---|---|---|---|
| Продажи | 1000 | 1500 | 2000 |
| Прибыль | 800 | 600 | 1200 |
| Площадь | 50 | 150 | 80 |
Данные
Предположим, что у нас есть таблица следующего вида:

Наша задача - развернуть таблицу, чтобы получить в строках данные по каждому магазину. То есть итоговая таблица должна быть следующей:

Загрузим файловый источник с примером в Analytic Workspace…
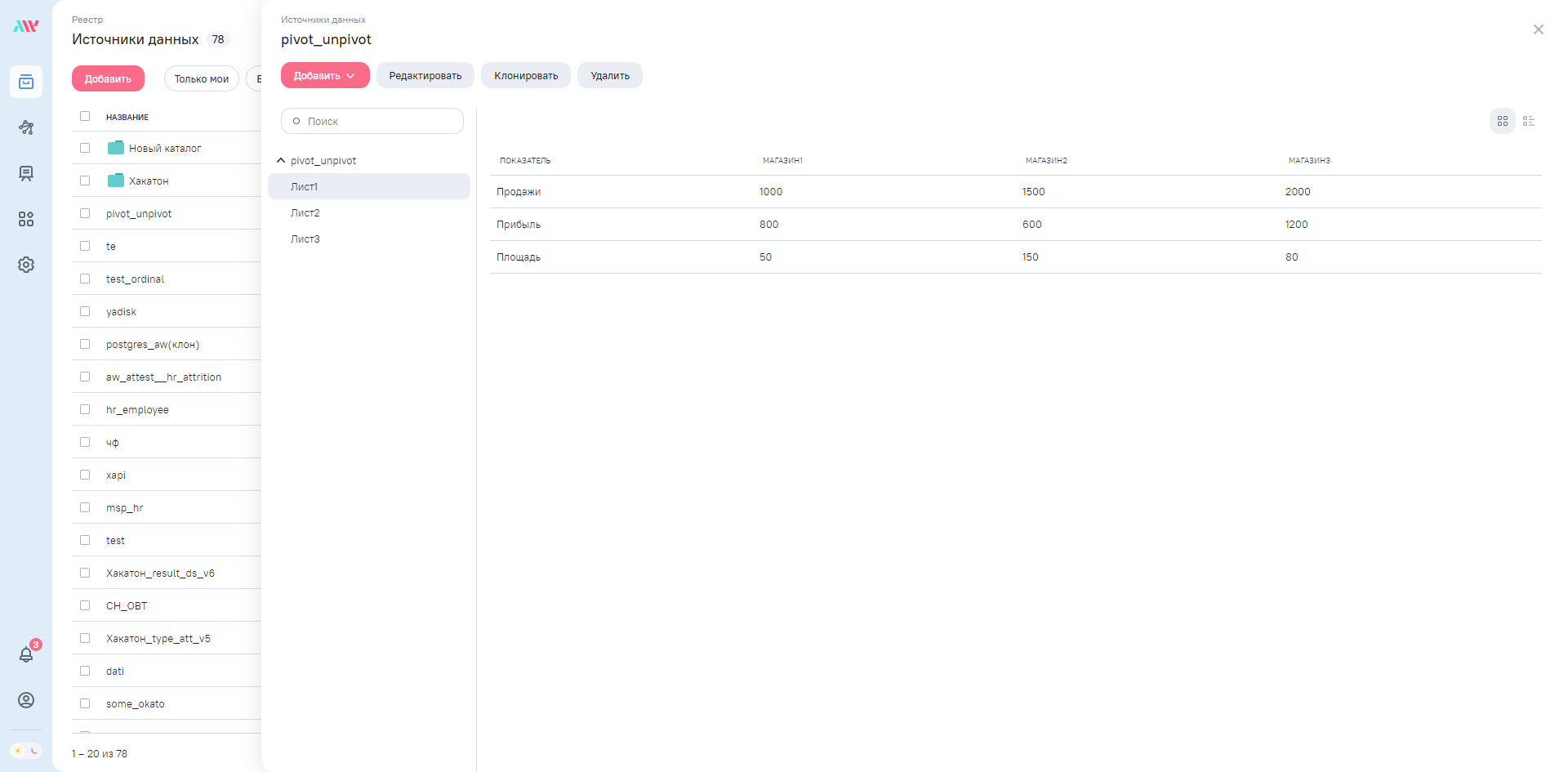
… и добавим его на схему новой модели
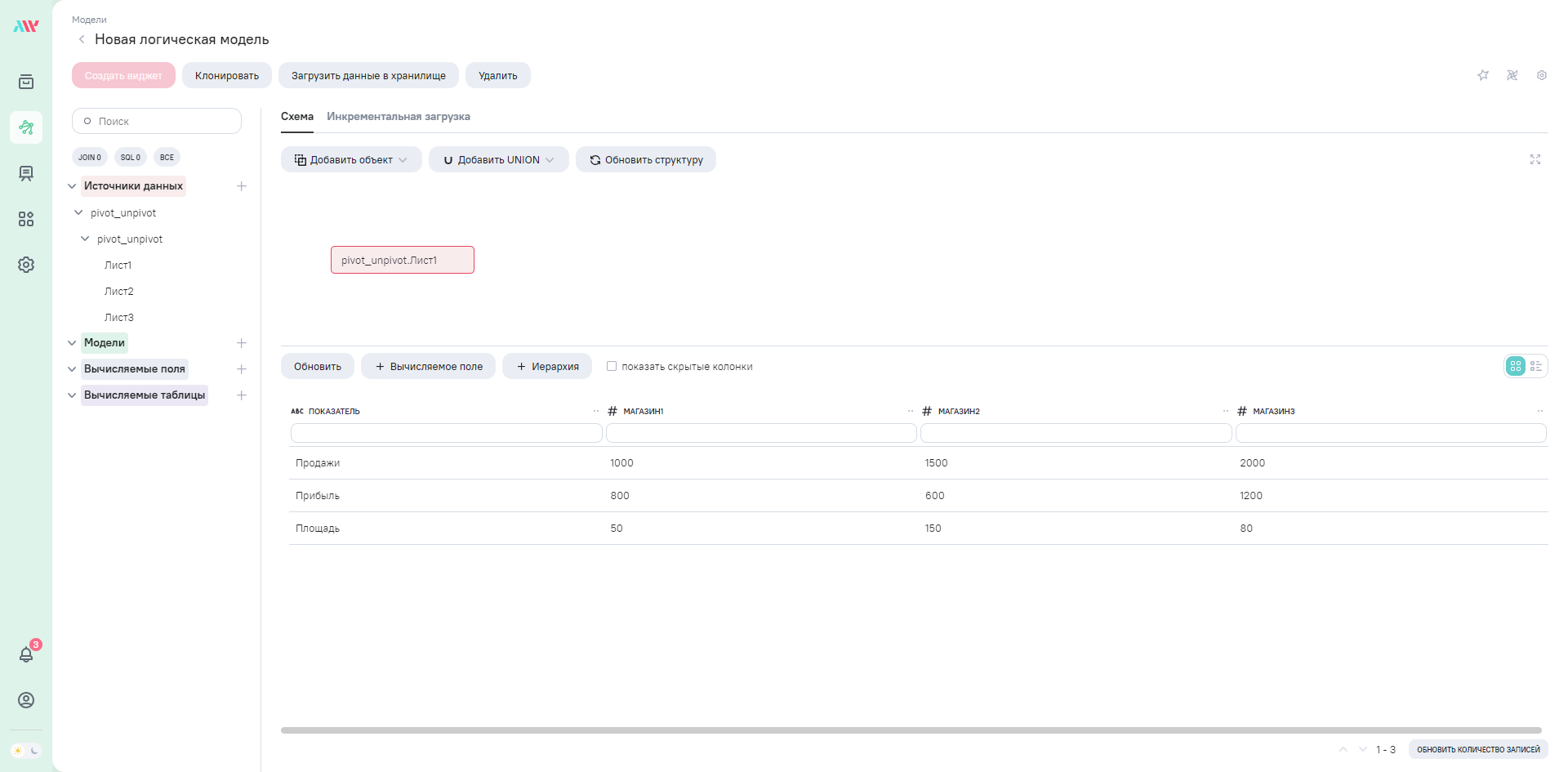
UNPIVOT
Первый вопрос, который надо задать перед составлением сводной таблицы: «Что мне нужно получить?». Наша исходная таблица фактически уже является сводной по магазинам(столбцы) в разрезе экономических показателей(строки). В результате транспонирования мы снова получим сводную таблицу, но уже по экономическим показателям(столбцы) в разрезе магазинов(строки).
Чтобы выполнить такое преобразование, сначала превратим нашу таблицу в плоскую, а затем снова соберем сводную, но уже по другим полям. Оператор UNPIVOT поворачивает таблицу, преобразуя столбцы в строки. UNPIVOT принимает два столбца (из таблицы или подзапроса) вместе со списком столбцов и создает строку для каждого столбца, указанного в списке.
Давайте посмотрим на примере. В первую очередь обратимся к данным нашего .xlsx листа через SQL и для удобства воспользуемся Common Table Expression.
with cte as (
SELECT
`Показатель`,
`Магазин1`,
`Магазин2`,
`Магазин3`
from `Лист1`
)
select * from cte
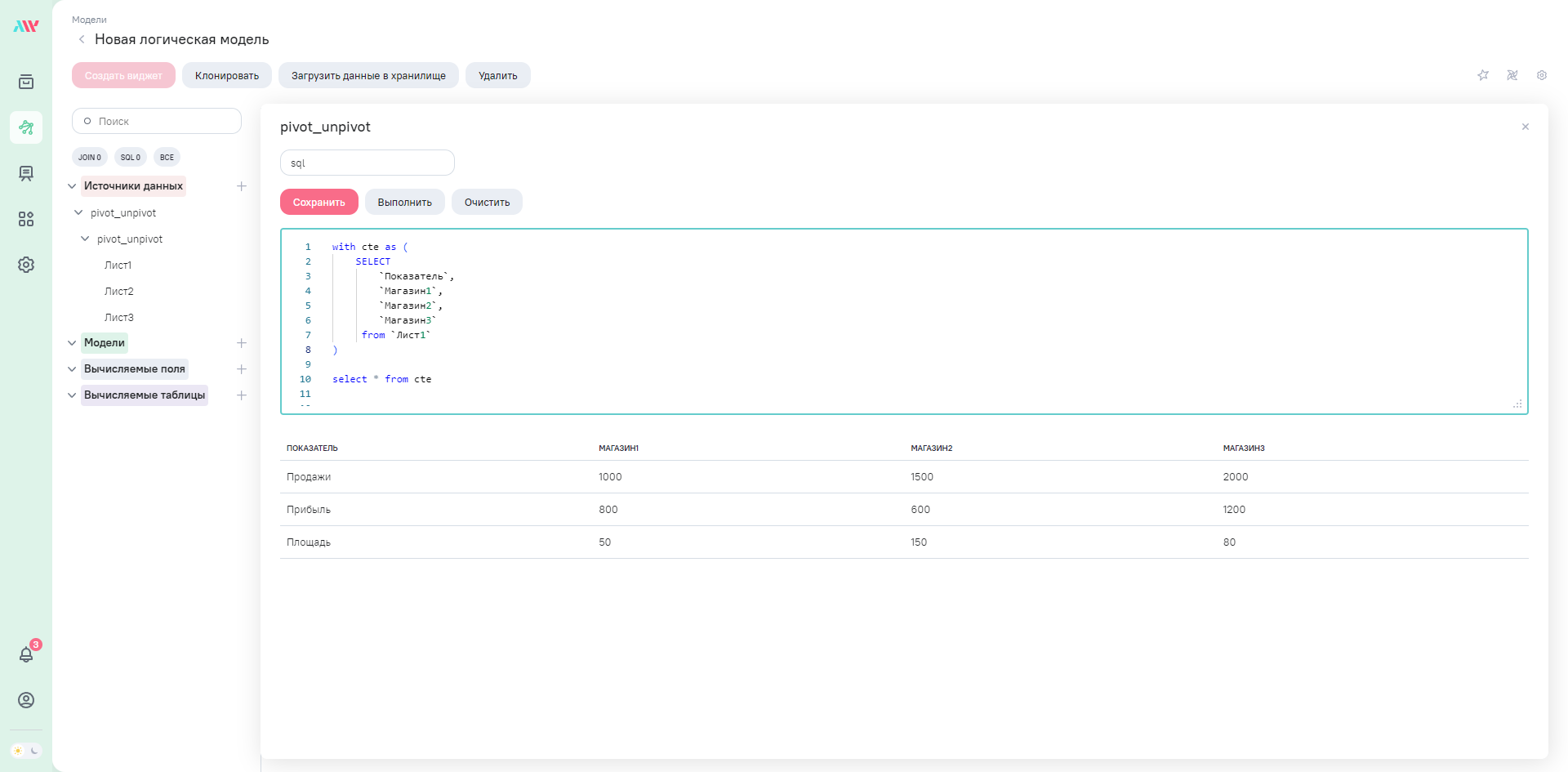
Теперь применим оператор UNPIVOT к нашей таблице cte.
select * from cte
unpivot (value for shop in (`Магазин1`,`Магазин2`,`Магазин3`))
Здесь мы должны указать:
-
value
название нового cтолбца со значениями в UNPIVOT-таблице -
for shop in (`Магазин1`,`Магазин2`,`Магазин3`)
название нового столбца(shop) в UNPIVOT-таблице, в котором будут хранится названия столбцов(`Магазин1`,`Магазин2`,`Магазин3`) исходной таблицы. Перечисляем их в операторе IN.
В итоге получим плоскую таблицу следующего вида:
PIVOT
Теперь из этой таблицы можем собрать новую сводную. Для этого воспользуемся оператором PIVOT, который поворачивает возвращающее табличное значение выражение, преобразуя уникальные значения одного столбца выражения в несколько выходных столбцов. В случае необходимости PIVOT также объединяет оставшиеся повторяющиеся значения столбца и отображает их в выходных данных.
Звучит сложно и непонятно, поэтому перейдем к практическому примеру.
Добавляем оператор PIVOT в наш запрос:
select * from cte
unpivot (value for shop in (`Магазин1`,`Магазин2`,`Магазин3`))
pivot (max(value) for `Показатель` in ('Продажи', 'Прибыль', 'Площадь'))
Синтаксис похож на UNPIVOT, только:
-
max(value)
Указываем функцию агрегации по полю со значениями из UNPIVOT-таблицы -
for `Показатель` in ('Продажи', 'Прибыль', 'Площадь'))
Указываем столбец(`Показатель`) UNPIVOT-таблицы, значения которого станут столбцами(‘Продажи’, ‘Прибыль’, ‘Площадь’) PIVOT-таблицы.
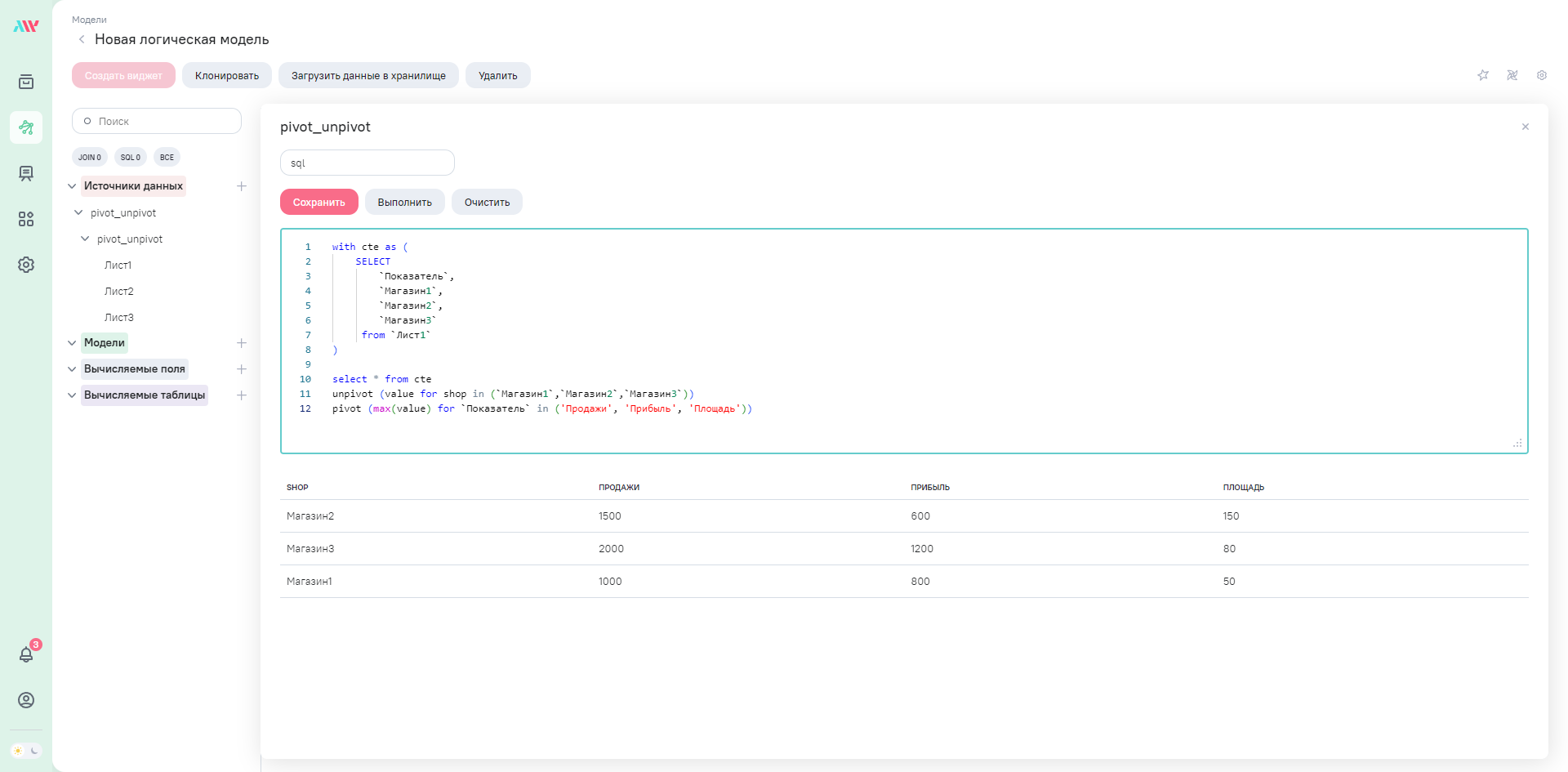
Осталось добавить сортировку по полю shop и мы получаем транспонированную таблицу, как изначально и задумывали.
