На практике в реальных данных очень часто встречаются пропуски. Причинами могут быть ошибки ввода данных, сокрытие информации, фрод. При работе с данными часто возникает необходимость обработать пустые значения в исходных данных.
В Analytic Workspace данная задача может быть выполнена различными способами, рассмотрим пример трансформации через ETL редактор.
Переход в редактор осуществляется по нажатию кнопки в верхнем правом углу при настройке модели.
ETL-процесс
Перед запуском трансформации, механизмы ETL обеспечивают выгрузку данных из источников и сохранение их в виде parquet-файлов во внутреннем хранилище системы. В процессе выполнения трансформации, система загружает данные каждой из таблиц в распределенные Spark-датафреймы (DataFrame) и выполняет над ними SQL-запрос, который соединяет их в единую денормализованную аналитическую таблицу.
Схема взаимодействия при работе с моделью представлена на рисунке.
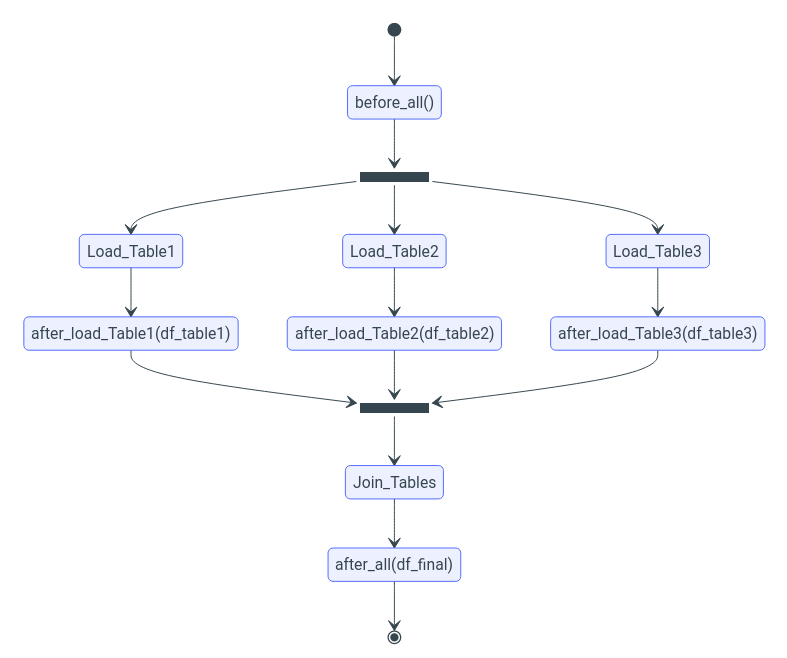
Таким образом существует несколько точек процесса через которые можно встроиться в процесс.
В примере будем убирать пустые значения после объединения всех таблиц, поэтому воспользуемся функцией after_all
Трансформация данных
Первым аргументом в функцию передается датафрейм с итоговой таблицей. Возвращать функция будет обработанный датафрейм. Полный код представлен ниже.
def after_all(df, spark, app, *args, **kwargs):
""" """
df_pd = df.toPandas()
df_pd.fillna({'sum_spicano_casov': 0}, inplace=True)
return spark.createDataFrame(df_pd)
Для удобства будем использовать возможности библиотеки Pandas. Преобразуем датафрейм Apache Spark в Pandas
df_pd = df.toPandas()
Для обработки пустых значений воспользуемся методом fillna. Первым параметром передаем объект с названиями столбцов и новыми значениями для пустых ячеек. Указываем параметр inplace=True для изменения датафрейма “на месте”. В примере для всех NaN значений в столбце ‘sum_spisano_casov’ установим 0. Таким образом можно явно указать к каким столбцам будут применены изменения.
df_pd.fillna({'sum_spicano_casov': 0}, inplace=True)
Для обработки значений во всех столбцах достаточно указать только новое значение для ячеек с NaN.
df_pd.fillna(0)
После внесенных изменений функция должна вернуть Apache Spark датафрейм. Для этого преобразуем фрейм Pandas обратно в Apache Spark.
return spark.createDataFrame(df_pd)
Синхронизация данных в модели
ETL скрипт можно протестировать на тестовых данных. После настройки необходимо опубликовать скрипт.

В модели необходимо загрузить обновленные данные в хранилище.
