При работе с данными часто возникает необходимость заполнения вычисляемой таблицы данными из таблицы источника. Для этих целей Apache Spark предоставляет объект хранилища.
Рассмотрим подобный сценарий на примере с 2 таблицами:
-
test_data_etl.Sheet1 – таблица из загруженного источника данных;
|-- sheet1__id: long (nullable = true)
|-- title: string (nullable = true)
|-- value: long (nullable = true) -
test_virtual_2 – созданная вычисляемая таблица.
|-- id: long (nullable = true)
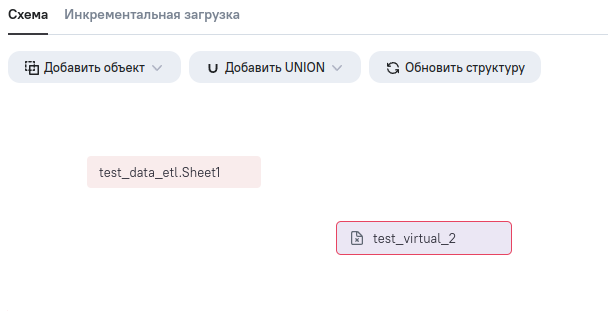
Попробуем заполнить столбец id вычисляемой таблицы идентификаторами из первой таблицы.
Для этого перейдем в редактор ETL.
Для обработки каждой таблицы используется функция с сигнатурой вида:
def after_load_[имя_таблицы](df, spark, app, *args, **kwargs)
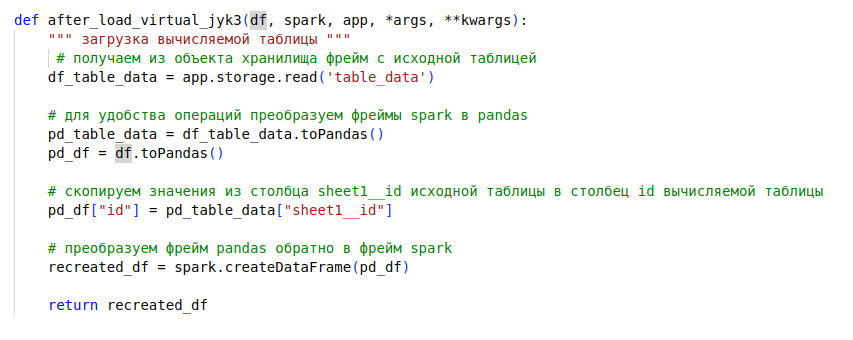
Во-первых, необходимо обратиться к таблице с исходными данными

Свойство storage объекта app обеспечивает интерфейс для сохранения и последующего чтения данных из внутреннего хранилища. Сохраним в него spark фрейм нашей таблицы.
Следущим шагом будет заполнение вычисляемой таблицы(см.комментарии в коде).
После выполненных преобразований не забываем опубликовать скрипт и синхронизировать данные в хранилище.
Теперь вычисляемая таблица заполнена нужными значениями.
Стоит отметить, что выбор реализации заполнения данных и внутренней логики функций after_load зависит от конкретной задачи. В данной статье демонстрируется механизм работы с хранилищем Storage и фреймами данных. Полный код скрипта представлен ниже.
-----------------------------------------------------------------------------------
Cкрипт для обработки модели 2574
-----------------------------------------------------------------------------------
def after_load_sheet1(df, spark, app, *args, **kwargs):
“”" загрузка таблицы из источника данных"“”
# сохраняем в объект хранилища фрейм с исходной таблицей с ключом “table_data”
app.storage.save(‘table_data’, df)
return df
def after_load_virtual_jyk3(df, spark, app, *args, **kwargs):
“”" загрузка вычисляемой таблицы “”"
# получаем из объекта хранилища фрейм с исходной таблицей
df_table_data = app.storage.read(‘table_data’)
# для удобства операций преобразуем фреймы spark в pandas
pd_table_data = df_table_data.toPandas()
pd_df = df.toPandas()
# скопируем значения из столбца sheet1__id исходной таблицы в столбец id вычисляемой таблицы
pd_df["id"] = pd_table_data["sheet1__id"]
# преобразуем фрейм pandas обратно в фрейм spark
recreated_df = spark.createDataFrame(pd_df)
return recreated_df